[논문리뷰] Align3R: Aligned Monocular Depth Estimation for Dynamic Videos
CVPR 2025. [Paper] [Page] [Github]
Jiahao Lu, Tianyu Huang, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, Yuan Liu
HKUST | CUHK | HKU | ShanghaiTech | WHU | TAMU | NTU
4 Dec 2024
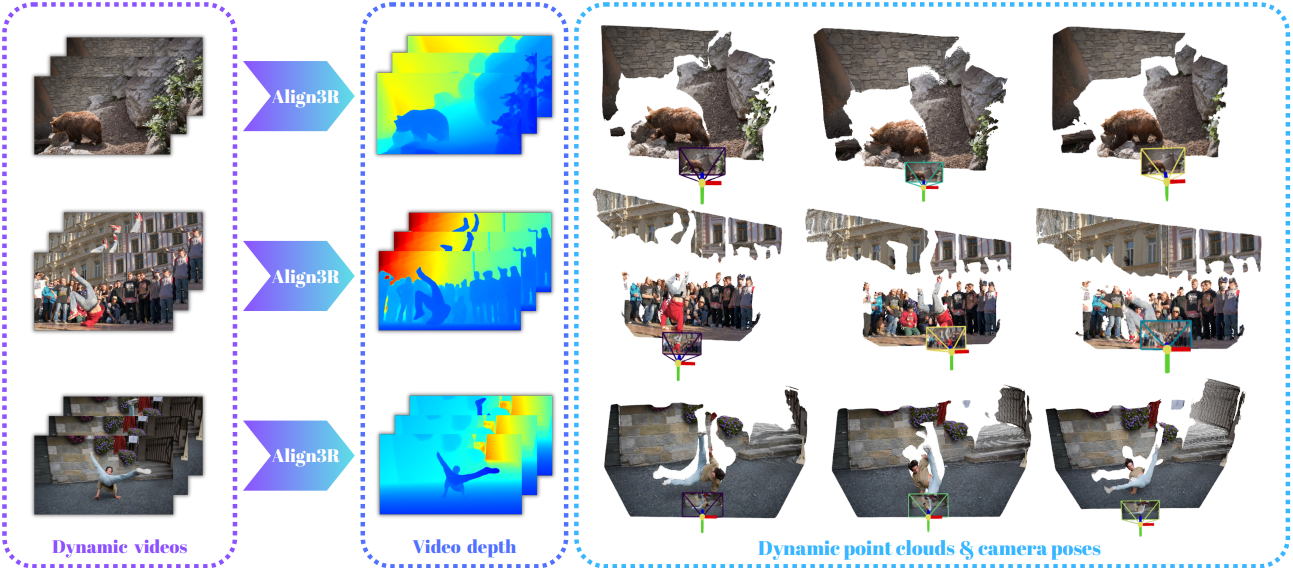
Introduction
본 논문에서는 monocular video에서 일관된 동영상 깊이 추정을 위한 Align3R이라는 새로운 방법을 제안하였다. Align3R의 핵심 아이디어는 monocular depth estimator를 DUSt3R와 결합하는 것이다. Monocular depth estimator는 각 프레임에 대해 세밀한 디테일로 고품질 깊이 추정이 가능하다. DUSt3R는 두 프레임을 정렬하기 위해 coarse한 3D 쌍별 포인트 맵을 예측할 수 있지만, 프레임 간 일관성을 유지할 수 없다. 따라서 Align3R은 정확하고 고품질의 동영상 깊이 추정을 위해 두 모델의 장점을 결합하여 다음 세 가지 특징을 보여준다.
- 동영상 diffusion 기반 방법과 비교할 때 쌍별 포인트 맵을 예측하는 방법만 학습하면 되므로 학습이 훨씬 쉽다.
- 원래 DUSt3R 모델과 비교할 때 depth map에서 더 많은 디테일을 예측할 수 있다.
- Align3R은 기존의 SfM 파이프라인으로는 어려운 동적 동영상의 카메라 포즈 추정을 자연스럽게 지원한다.
Monocular depth estimation을 DUSt3R와 결합하는 것은 간단하지 않다. 간단한 방법은 DUSt3R의 쌍별 포인트 맵 예측을 제약 조건으로 사용하여 여러 프레임의 monocular depth estimation을 직접 정렬하는 사후 최적화 전략이다. 그러나 동적 동영상에서 DUSt3R를 fine-tuning한 후에도 이 전략은 좋은 결과를 보여주지 못한다.
대신, 저자들은 DUSt3R fine-tuning에서 monocular depth estimation을 활용하는 더 나은 조합 전략을 제안하였다. 이 전략은 fine-tuning된 DUSt3R 모델이 정렬할 monocular depth map을 인식하도록 효과적으로 만든다. 구체적으로, 추정된 monocular depth map을 unprojection하여 3D 포인트 맵을 얻은 다음, 포인트 맵을 인코딩하기 위해 추가 Transformer를 적용하고 마지막으로 인코딩된 feature를 DUSt3R의 디코더에 더한다. 이 전략에서는 fine-tuning 과정에서 monocular depth 추정값을 DUSt3R 모델의 포인트 맵 예측에 주입한다. 이를 통해 더욱 상세한 포인트 맵 예측이 가능할 뿐만 아니라, fine-tuning된 모델이 입력 depth map의 스케일 차이에 대한 정보를 얻게 된다. 그 후에는 DUSt3R의 최적화 과정을 따라 다양한 프레임의 depth map을 예측하기만 하면 된다.
Method
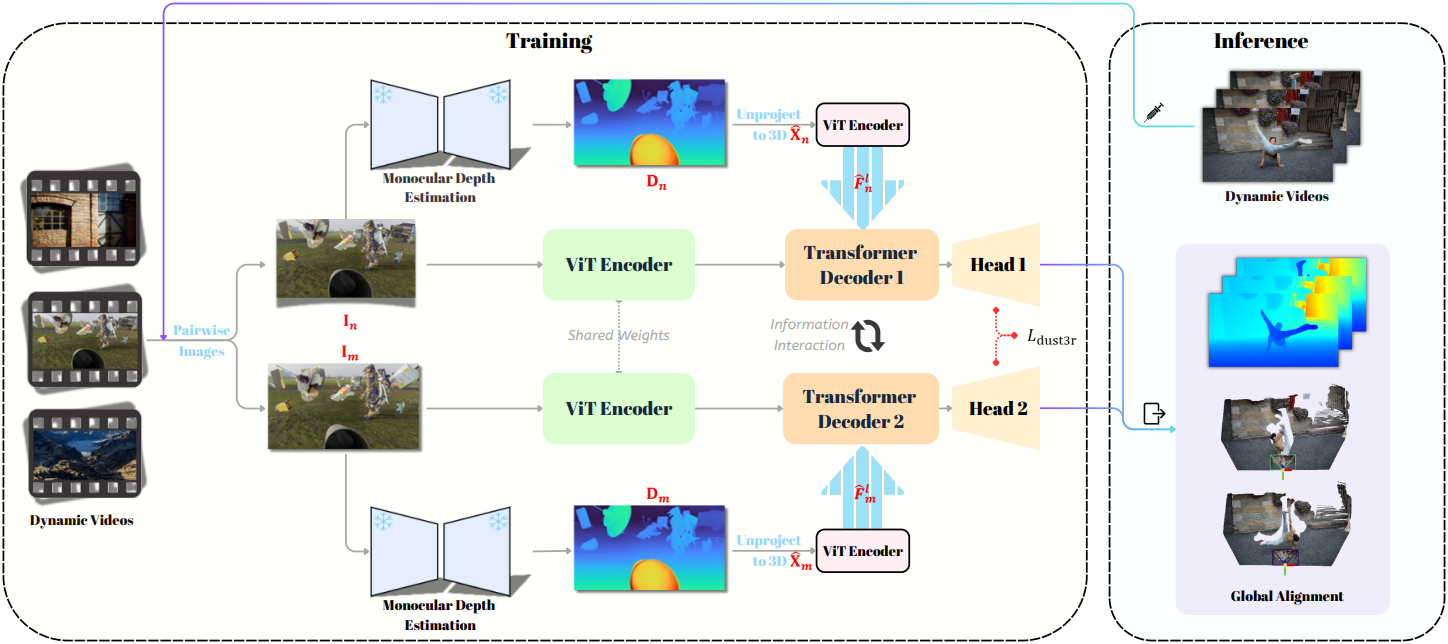
1. Incorporating Monocular Depth Estimation
본 논문은 Depth Pro 또는 Depth Anything V2에서 예측된 monocular depth map을 DUSt3R에 통합하는 메커니즘을 설계하는 것을 목표로 한다. 간단하게 입력 RGB 이미지에 depth map을 직접 concat하는 방법은 사전 학습된 DUSt3R 인코더의 feature 분포를 손상시킨다. 대신, 저자들은 ControlNet에서 영감을 받아 새로운 ViT에서 depth map의 feature를 추출하고, 이를 DUSt3R 디코더에 주입한다. 이 과정에서 fine-tuning 전 원래 예측은 손상되지 않는다.
Depth to points
DUSt3R 모델의 예측은 두 이미지에 대한 포인트 맵이므로 더 나은 수렴을 위해 추정된 깊이를 포인트 맵으로 변환한다. 추정된 depth map을 3D 공간으로 unprojection하여 3D 포인트 맵 \(\hat{\textbf{X}}_n, \hat{\textbf{X}}_m \in \mathbb{R}^{H \times W \times 3}\)을 생성한다. 이 unprojection 프로세스에는 입력 이미지의 intrinsic이 필요하다.
Depth Pro와 같은 초점 거리 예측이 있는 모델의 경우, 예측된 초점 거리를 사용하여 intrinsic을 구성한다. Depth Anything V2와 같은 초점 거리 예측이 없는 모델의 경우, 초점 거리를 고정된 값으로 설정한다. 예측된 깊이 값의 숫자 범위가 크기 때문에 unprojection된 포인트 맵의 각 축을 [-1,1] 범위에 별도로 정규화하여 안정적인 모델 학습을 보장한다.
Point map ViT
다음으로, $i = n$ 또는 $i = m$인 각 포인트 맵 \(\hat{\textbf{X}}_i\)에 대해 표준 패치 임베딩 방법을 적용하여 포인트 맵을 패치로 나눈다.
\[\begin{equation} \hat{\textbf{X}}_i^\prime = \textrm{PatchEmbed} (\hat{\textbf{X}}_i) \in \mathbb{R}^{H^\prime \times W^\prime \times C} \end{equation}\]\(\hat{\textbf{X}}_i^\prime\)에 self-attention 메커니즘을 적용하여 multi-level feature \(\hat{\textbf{F}}_i^{(1)}, \ldots, \hat{\textbf{F}}_i^{(s)}\)를 생성하고, 이 feature들을 DUSt3R 디코더에 주입한다. 원래 DUSt3R 모델의 예측을 망치지 않기 위해 feature 융합에 zero convolution을 사용한다.
\[\begin{equation} \hat{\textbf{E}}_i^{(l)} = \textrm{ZeroConv} (\hat{\textbf{F}}_i^{(l)}) + \textbf{E}_i^{(l)}, \quad l = 1, \ldots, s \end{equation}\](\(\textbf{E}_i^{(l)}\)는 DUSt3R 디코더의 $l$번째 레이어에 의해 생성된 feature map, \(\hat{\textbf{E}}_i^{(l)}\)는 주입된 포인트 맵 feature가 포함된 feature map)
2. Fine-tuning on Dynamic Videos
원래 DUSt3R 모델은 정적 장면에서만 학습되었으며 동적 동영상을 올바르게 처리할 수 없다. 따라서 저자들은 GT depth map이 있는 동적 동영상에서 DUSt3R 모델과 추가 포인트 맵 Transformer를 fine-tuning했다. DUSt3R의 강력한 feature 추출 능력을 유지하기 위해, 인코더는 고정되고 디코더와 추가 포인트 맵 Transformer만 fine-tuning된다. DUSt3R를 따라 fine-tuning loss는 다음과 같이 정의된다.
\[\begin{equation} L_\textrm{dust3r} = \| \frac{1}{z} \textbf{X}_v^c - \frac{1}{\bar{z}} \bar{\textbf{X}}_v^c \|_2 \end{equation}\](\(v \in \{n, m\}\)은 뷰 인덱스, $\textbf{X}$와 $\bar{\textbf{X}}$는 예측 포인트 맵과 GT 포인트 맵, $z$와 $\bar{z}$는 예측 포인트 맵과 GT 포인트 맵을 정규화하는 데 사용되는 scaling factor)
Scaling factor $z$와 $\bar{z}$는 단일 이미지 내의 모든 유효 픽셀을 사용하여 계산된다.
깊이 필터링
DUSt3R fine-tuning에서 눈에 띄는 문제는 GT 포인트 맵의 수치 범위가 매우 크다는 것이다. 깊이 값이 큰 원거리 포인트들은 학습 loss를 크게 차지한다. 그러나 baseline 길이가 제한된 이미지 쌍의 경우, 깊이 값이 큰 지점의 차이가 작기 때문에 정확하게 예측하기 어렵고, 이러한 원거리 포인트들은 근거리 물체만큼 중요하지 않다. 따라서 저자들은 400m를 넘는 깊이 영역을 필터링하여 멀리 있는 물체가 예측 정확도에 미치는 영향을 줄였다.
3. Inference on Long Videos
동적 동영상에 대해 모델을 fine-tuning한 후, 주어진 동적 동영상에 대한 쌍방향 포인트 맵을 예측하는 데 이 모델을 적용한다. 그런 다음, DUSt3R를 따라 각 프레임에 대해 일관된 depth map과 카메라 포즈를 구한다. 그러나 30프레임 이상의 긴 동영상의 경우, DUSt3R의 기존 최적화 전략이 메모리를 너무 많이 소모하여 GPU 메모리 부족을 유발한다. 따라서 저자들은 메모리 소모를 줄이기 위해 계층적 최적화를 적용했다.
계층적 최적화
긴 동영상 시퀀스가 주어지면, 동영상을 미리 정의된 길이 $M = 10$ 또는 $M = 20$의 $K$개 클립으로 나눈다. 각 클립에서 하나의 이미지를 키프레임으로 사용하여 길이 $K$의 키 프레임 클립을 구성한다. 키 프레임 클립에 글로벌 정렬을 수행하여 각 키프레임의 depth map, 카메라 포즈, 초점 거리를 초기화한다. 그런 다음, 분할된 각 클립에 대해 로컬 정렬을 적용하여 나머지 프레임의 depth map, 카메라 포즈, 초점 거리를 계산한다. 이러한 글로벌-로컬 계층적 최적화는 제한된 프레임을 가진 짧은 클립만 최적화하여 일관성을 유지하면서 메모리와 시간 소모를 효과적으로 줄인다.
Experiments
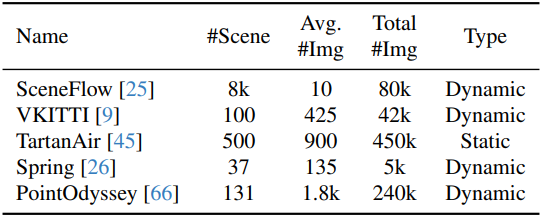
- 데이터셋: Sceneflow, VKITTI, TartanAir, Spring, PointOdyssey
- 구현 디테일
- 입력 해상도: 512$\times$288, 512$\times$336, 512$\times$256
- feature layer 수: $s = 6$
- optimizer: AdamW
- learning rate: $5 \times 10^{-5}$
- batch size: 12
- epoch: 50
- epoch당 이미지 쌍 27,750개
- GPU: RTX 4090 6개, 학습에 20시간 소요
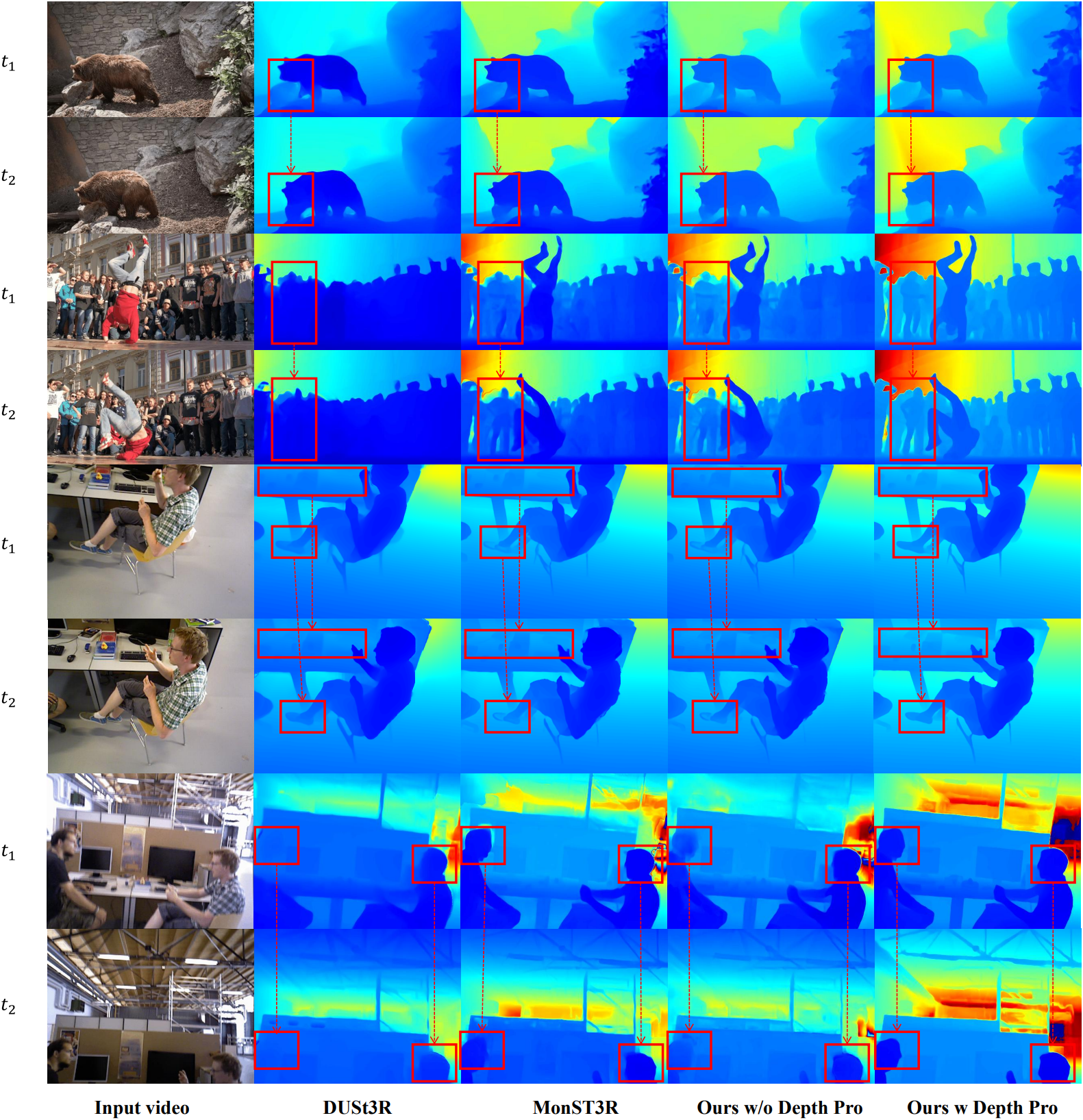
1. Video depth estimation
다음은 동영상 깊이 추정 결과이다.
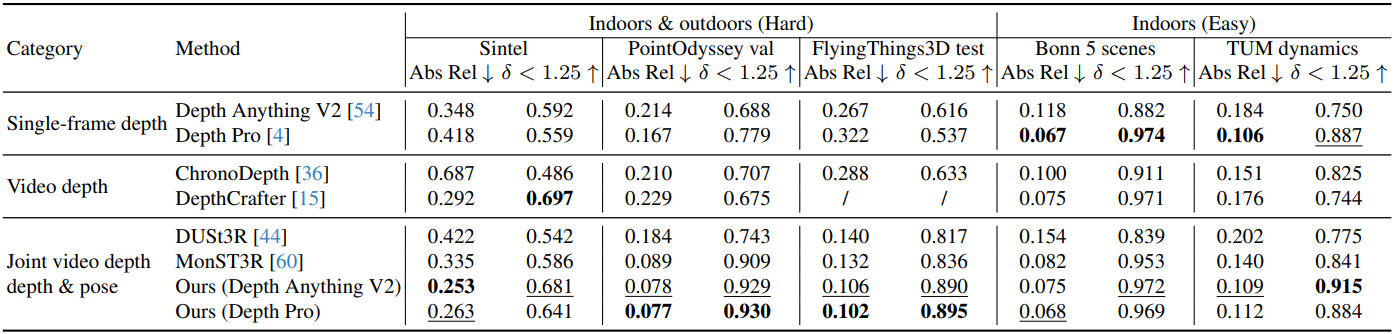
2. Camera pose estimation
다음은 카메라 포즈 추정 결과이다.
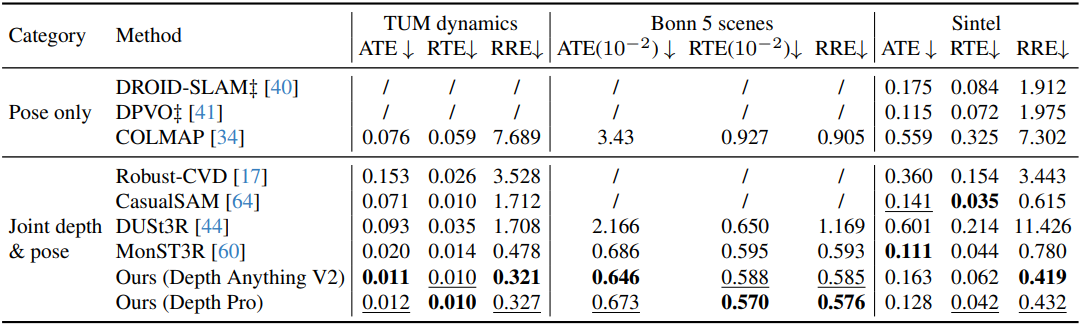
3. Ablation study
다음은 fine-tuning 전략에 대한 ablation study 결과이다.
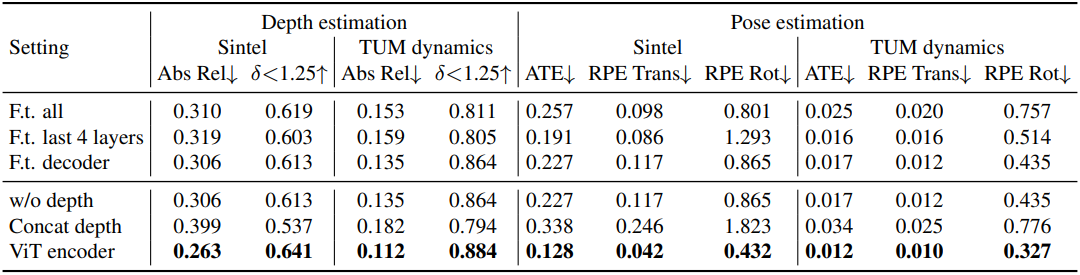
다음은 깊이 통합 방법에 대한 ablation study 결과이다.

다음은 계층적 최적화 (HO)에 대한 ablation study 결과이다.
