[논문리뷰] AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
ICCV 2025. [Paper] [Page]
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang
Fudan University | Microsoft Research Asia
10 Jun 2024

Introduction
Text-guided video prediction (TVP) task는 몇 가지 어려운 과제를 안고 있다. 초기 프레임을 이해하고, 초기 프레임을 텍스트에 맞춰 정렬하며, 일관성 있는 후속 프레임을 생성해야 한다. 텍스트 기반 동영상 생성 모델과 비교했을 때, TVP는 지시 사항을 따르는 생성된 동영상의 정확도에 더 중점을 둔다.
최근 대부분의 방법은 텍스트 기반 이미지 생성 모델을 TVP로 확장하여 이 문제를 해결하고 있다. 이러한 모델들은 강력한 창의적 능력을 가지고 있지만, 동영상 사전 정보가 부족하다. 소량의 도메인별 데이터로 이러한 모델을 학습시키면 동영상의 일관성과 안정성이 떨어지는 경우가 많다. 그러나 방대한 데이터셋으로 사전 학습된 동영상 생성 모델은 동영상의 동적 특성에 대한 강력한 사전 정보를 학습했다. 따라서 이러한 잘 사전 학습된 동영상 생성 모델을 특정 도메인에 적용하는 것은 상당한 잠재력을 가지고 있다.
본 논문에서는 image-to-video 생성을 위한 base model로 Stable Video Diffusion (SVD)을 선택했다. 그림 1에서 볼 수 있듯이, SVD를 TVP에 적용하기 위해서는 두 가지 주요 과제에 직면한다. 첫째, 텍스트 조건을 설계하고 이를 diffusion model에 주입하여 동영상 생성을 가이드하는 방법이다. 둘째, 현재 모델을 타겟 데이터셋에 맞게 낮은 학습 비용으로 조정하여 생성된 동영상이 실제 시나리오와 더욱 유사하도록 하는 방법이다.
초기 프레임과 텍스트를 기반으로 미래 프레임을 예측하는 것은 직관적으로 어려운 과제이다. 단일 텍스트만으로는 동영상의 시간적 역동성을 완전히 포착할 수 없기 때문이다. 이러한 문제를 해결하기 위해, 본 논문에서는 초기 프레임과 텍스트로부터 미래 동영상의 상태를 예측하는 MLLM을 도입했다. 또한, 저자들은 기존 제어 정보를 통합하기 위해 두 개의 branch를 가진 Dual Query Transformer (DQFormer) 아키텍처를 설계했다. 한 branch는 텍스트와 시각 정보로부터 멀티모달 제어 정보를 학습하는 데 사용하고, 다른 branch는 텍스트 상태 조건을 프레임 수준 제어로 분해하는 데 사용된다. 마지막으로, 완전한 멀티모달 조건(MCondition)을 cross-attention 메커니즘을 통해 UNet에 입력한다. 또한, 모델을 타겟 데이터셋에 맞게 조정하고 예측 품질을 향상시키기 위해 spatial adapter, short-term temporal adapter, long-term temporal adapter를 설계하여, 적은 파라미터와 계산 비용으로 대상 동영상 예측에 적용할 수 있도록 했다.
Method
1. Overview
Task 정의
$N$개의 프레임으로 구성된 동영상 \(\{V\}_{i=1}^N\)에 대해, 처음 $K$개의 프레임과 텍스트 설명 $t$가 주어졌다고 가정한다. 목표는 주어진 초기 $K$개의 프레임과 텍스트 설명 $t$를 기반으로 이후 $N-K$개의 프레임을 예측하는 것이다. 현재 단일 이미지로부터 $N$개의 동영상 프레임을 자동으로 생성할 수 있는 잘 사전 학습된 image-to-video 모델이 있다고 가정한다. 주요 목표는 이 사전 학습된 생성 모델을 최대한 활용하여 텍스트 조건 정보를 통합하고, 특정 데이터셋의 TVP task에 신속하게 적용하는 것이다.
파이프라인
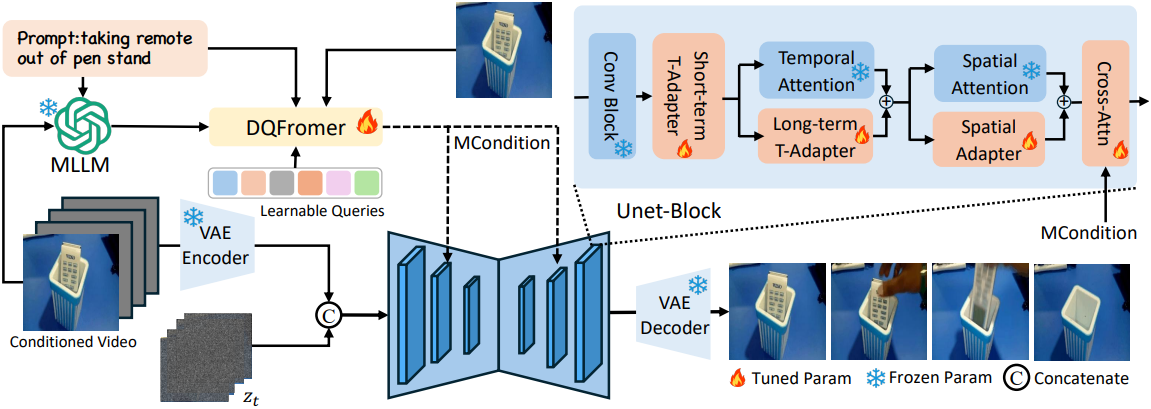
본 모델은 Stable Video Diffusion (SVD)을 기반으로 구축되었다. 처음 $K$개의 프레임을 조건 프레임으로 사용한다. 나머지 $N-K$개의 프레임은 마스크를 사용하여 완성한다. VAE 인코더를 통해 컨디셔닝된 latent 데이터를 얻은 후, 이를 채널 차원을 따라 noise가 더해진 latent 데이터 표현과 concat한다. 그런 다음, 특별히 설계된 DQFormer를 통해 주입된 멀티모달 조건(MCondition)에 의해 제어되는 UNet은 $N-K$개의 latent 데이터의 시퀀스의 noise를 제거하고 예측한다. 마지막으로, VAE 디코딩을 통해 전체 $N$개의 동영상 프레임을 재구성한다.
2. Text Condition Injection
Video Prediction Prompting

Text-to-image 모델의 성공과 달리, text-to-video 모델은 격차를 보인다. 이는 텍스트-동영상 데이터셋을 구축하는 것이 텍스트-이미지 데이터셋보다 훨씬 어렵기 때문이다. 또한, 하나의 문장으로 이미지를 정확하게 설명할 수는 있지만, 동영상의 동적인 변화를 전달하기에는 불충분하다.
이러한 문제를 해결하기 위해, 본 논문에서는 초기 프레임과 텍스트 명령을 입력으로 받아 동영상의 미래 상태를 예측할 수 있는 MLLM (ex. LLAVA)을 사용하였다. 위 그림에서 볼 수 있듯이, 주어진 텍스트 “lifting up one end of a tablet box, then letting it drop down”에 대해, 모델은 동영상의 네 가지 상태, 즉 초기 상태, 한쪽 끝을 들어 올리는 상태, 한쪽 끝을 놓는 상태, 그리고 최종 상태를 예측할 수 있다.
DQFormer
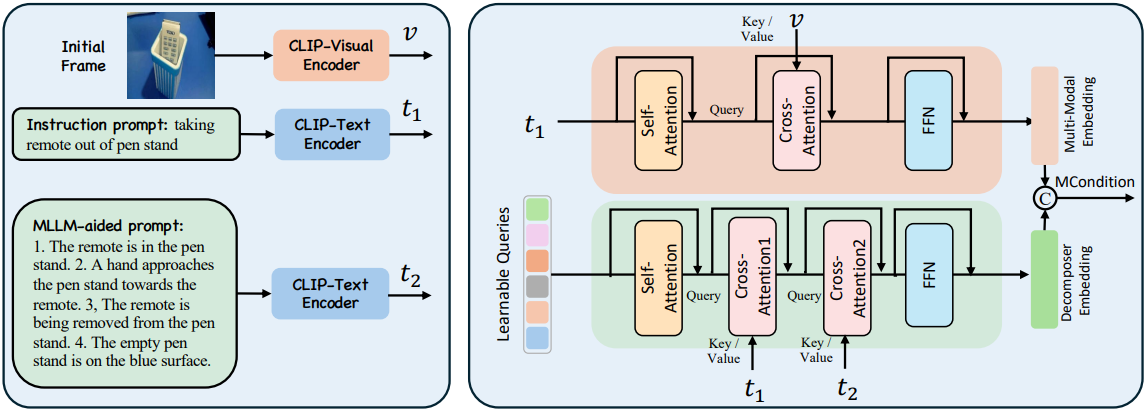
MLLM에서 예측한 텍스트와 동영상의 첫 번째 프레임 및 텍스트 명령을 통합하여 완전한 멀티모달 조건(MCondition)을 구성해야 한다. 이를 위해 저자들은 다양한 모달리티의 조건 정보를 병합하는 Dual Query Transformer (DQFormer) 아키텍처를 설계했다.
먼저 CLIP Visual Encoder를 사용하여 초기 프레임의 feature $v$를 추출한 다음, CLIP Text Encoder에 명령 프롬프트와 MLLM 프롬프트를 입력하여 각각 텍스트 feature $t_1$과 $t_2$를 추출한다.
상위 branch는 텍스트 명령과 초기 프레임 간의 정렬을 통해 멀티모달 임베딩을 얻는 데 사용된다. 글로벌 명령 임베딩 $t_1$은 먼저 multi-head self-attention을 거친 후, $v$와의 cross-attention을 계산하고, 마지막으로 feed-forward network (FFN)를 통해 멀티모달 임베딩을 얻는다.
\[\begin{equation} \textrm{multimodal embedding} = \textrm{SoftMax} \left( \frac{(W_1^Q \textrm{SelfAttn}(t_1)) (W_1^K v)^\top}{\sqrt{d_1}} \right) (W_1^V v) \end{equation}\](FFN과 residual connection은 생략)
하위 branch는 프롬프트 feature를 프레임 수준 조건으로 분해하도록 설계되었다. 먼저, 학습 가능한 query 임베딩 \(Q \in \mathbb{R}^{(N \cdot N_t) \times C}\)를 설정한다. 여기서 $N$은 프레임 수이고, $N_t = 77$는 query 수이다. 먼저 이를 self-attention layer로 보내고, 명령어 임베딩 $t_1$과의 cross-attention을 계산하여 각 프레임에 대해 분해한다. 그 다음 MLLM 임베딩 $t_2$와의 cross-attention을 계산하여 각 프레임에 해당하는 multi-state embedding을 분해한다. 마지막으로, FFN을 통해 분해된 임베딩을 얻는다.
\[\begin{equation} Q^\prime = \textrm{SoftMax} \left( \frac{(W_2^Q \textrm{SelfAttn}(Q)) (W_1^K t_1)^\top}{\sqrt{d_2}} \right) (W_1^V t_1) \\ \textrm{decomposed embedding} = \textrm{SoftMax} \left( \frac{(W_3^Q Q^\prime) (W_3^K t_2)^\top}{\sqrt{d_3}} \right) (W_3^V t_2) \end{equation}\]마지막으로, feature들은 concat된다.
\[\begin{equation} \textrm{MCondition} = [\textrm{multimodal embedding}; \textrm{decomposed embedding}] \end{equation}\]MCondition을 얻은 후, 이를 key와 value로 사용하여 cross-attention 메커니즘을 통해 latent 표현에 주입한다.
3. Adapter Modeling
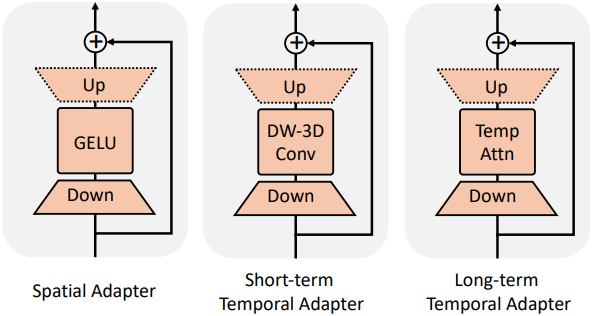
Spatial Adapter
저자들은 타겟 데이터셋의 공간적 분포에 맞게 모델을 적응시키기 위해 spatial adapter를 설계했으며, 이는 spatial self-attention과 나란히 추가된다. 이 어댑터는 GELU activation을 사용하는 다운샘플링 linear layer와 업샘플링 linear layer로 구성된 간단한 구조이다. 원래 모델 구조가 손상되지 않도록 ControlNet을 따라 업샘플링 linear layer를 0으로 초기화한다.
\[\begin{equation} \textrm{S-Adapter}(\textbf{X}) = \textbf{X} + \textbf{W}_\textrm{up} (\textrm{GELU}(\textbf{W}_\textrm{down} (\textbf{X}))) \end{equation}\]Shot-term Temporal Adapter
저자들은 동영상의 동적 모션 분포를 타겟 데이터셋으로 전송하기 위해 두 종류의 temporal adapter를 설계했다. Short-term temporal adapter는 두 linear layer 사이에 Depth-wise 3D Convolution을 통합한다.
\[\begin{equation} \textrm{ST-Adapter}(\textbf{X}) = \textbf{X} + \textbf{W}_\textrm{up} (\textrm{3D-Conv}(\textbf{W}_\textrm{down} (\textbf{X}))) \end{equation}\]Long-term Temporal Adapter
Long-term temporal adapter는 두 linear layer 사이에 temporal self-attention을 통합했다. 인접 프레임 간의 시간적 관계를 모델링하는 경향이 있는 convolution 기반 short-term temporal adapter와 달리, 이 어댑터는 글로벌 시간 모델링에 초점을 맞추도록 설계되었다.
\[\begin{equation} \textrm{LM-Adapter}(\textbf{X}) = \textbf{X} + \textbf{W}_\textrm{up} (\textrm{Self-Attn}(\textbf{W}_\textrm{down} (\textbf{X}))) \end{equation}\]학습 과정에서 기존 UNet의 가중치는 고정하고 새로 추가된 세 가지 유형의 어댑터에 대한 파라미터만 업데이트한다. 이 접근 방식은 GPU 메모리와 학습 비용을 절약할 뿐만 아니라 글로벌 overfitting과 모델 붕괴를 완화하는 데에도 도움이 된다.
Experiments
- 데이터셋: Something Something-V2 (SSv2), Bridge Data, EpicKitchens-100 (Epic100)
- 구현 디테일
- 해상도: 256$\times$256
- 학습 중에 VAE와 3D UNet은 고정
- DQFormer, 3가지 어댑터, cross-attention layer만 학습
- classifier-free guidance를 적용
- 프레임 조건에 대한 guidance scale $s_v$와 텍스트 조건에 대한 guidance scale $s_t$를 사용
1. Main Results
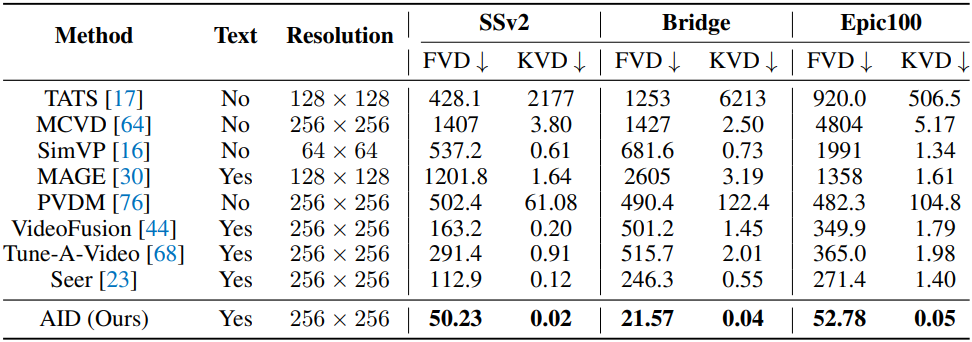
다음은 video prediction 성능을 비교한 결과이다.

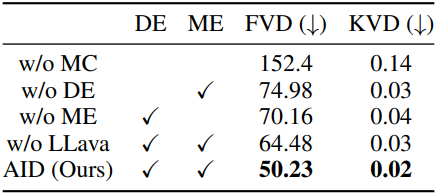
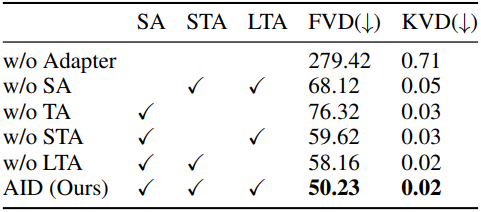
2. Ablation Study
다음은 (왼쪽) 조건과 (오른쪽) 어댑터에 대한 ablation 결과이다.