[논문리뷰] AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
CVPR 2025. [Paper] [Page]
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B. Lindell, Sergey Tulyakov
University of Toronto | Vector Institute | Snap Inc. | SFU
27 Nov 2024
VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control의 후속 논문
Introduction
인터넷 규모 데이터로 학습된 video diffusion model은 세계에 대한 풍부한 지식을 습득하였지만, 카메라 모션 제어와 같은 세분화된 제어 메커니즘을 노출하지 않기 때문에 이러한 지식의 대부분은 모델 내에 암시적으로 저장된다. 저자들은 video diffusion model에서 카메라 모션 제어를 기본 원칙부터 분석하고, 합성 품질을 저하시키지 않고 정확한 3D 카메라 컨디셔닝을 통합할 수 있는 몇 가지 방법을 개발하였다.
저자들은 분석을 위해 1억 개의 텍스트/동영상 쌍의 데이터셋에서 11.5B VDiT (video latent diffusion transformer)를 학습시켰다. 저자들은 이 모델에서 세 가지 핵심 연구를 수행하였으며, 이를 바탕으로 VD3D의 카메라 제어 솔루션을 픽셀 기반 diffusion model에서 latent 기반 diffusion model로 전환하고 성능을 크게 향상시켰다.
1. 카메라 모션의 스펙트럼 속성
저자들은 모션 제어의 통계적 특성을 연구하기 위해 VDiT 모델에서 생성된 동영상의 motion spectral volume (MSV)을 분석하였다. MSV는 주파수 스펙트럼의 다른 부분에 있는 에너지의 양을 보여준다. 즉, 저주파의 높은 에너지는 부드러운 모션을 나타낸다.
저자들은 카메라 모션과 장면 모션이 다양한 생성된 200개 동영상과 denoising process의 다양한 단계에서 MSV를 측정하였다. 그 결과, 카메라 모션은 주로 스펙트럼의 낮은 부분에 영향을 미치고 denoising 궤적에서 매우 일찍 (약 10%) 시작된다는 것을 관찰했다. 그런 다음 diffusion model은 본질적으로 coarse-to-fine하게 진행되므로 카메라 컨디셔닝을 저주파에 해당하는 denoising step들에만 주입하도록 제한한다. 그 결과 약 15% 더 높은 시각적 충실도, 약 30% 더 나은 카메라 추종, 그리고 장면 모션 저하를 완화하였다.
2. VDiT의 카메라 모션 지식
텍스트 전용 VDiT를 고려하고 해당 모델이 카메라에 대한 지식을 가지고 있는지, 그리고 이 지식이 아키텍처 내에서 어디에 표현되는지 확인하였다. 이 목표를 가지고 학습에 사용하지 않는 RealEstate10k 동영상을 VDiT에 공급하고 linear probing을 수행하여 카메라 포즈를 내부 표현에서 복구할 수 있는지 확인하였다.
분석 결과, VDiT가 암시적으로 내부에서 카메라 포즈 추정을 수행하고, 카메라 지식의 존재가 중간 레이어에서 최고조에 달하는 것으로 나타났다. 이는 카메라 신호가 초기 block에서 나타나서 이후 block이 후속 시각적 표현을 구축하는 데 의존할 수 있음을 의미한다. 따라서 컨디셔닝 체계를 조정하여 아키텍처의 처음 30%에만 영향을 미치도록 하여 학습 파라미터를 약 4배 줄이고, 학습 및 inference 가속을 15%, 시각적 품질을 10% 향상시켰다.
3. 학습 분포의 재조정
카메라 제어 아키텍처를 학습시키기 위한 일반적인 방법은 RealEstate10k에서 제공하는 카메라 포즈에 의존하는 것이다. 그러나 이 데이터셋에는 대부분 정적 장면이 포함되어 있어 fine-tuning된 동영상 모델의 모션이 상당히 저하된다. 이 문제를 해결하기 위해 저자들은 동적 장면과 정적 카메라가 있는 20,000개의 다양한 동영상들을 선별하였다. 데이터의 이러한 간단한 조정만으로도 포즈 컨디셔닝된 동영상 모델을 활성화하는 동시에 장면 역동성을 복구하기에 충분하다.
Method
1. Base model (VDiT)
Sora를 따라 대부분의 동영상 생성 모델은 diffusion 프레임워크를 사용하여 VAE의 latent space에서 대규모 transformer를 학습시켜 텍스트에서 동영상을 생성한다. Base model은 동일한 디자인을 채택하였다.
- Rectified flow parametrization
- VAE: CogVideoX의 VAE 사용 (16채널, 4$\times$8$\times$8만큼 압축)
- hidden dimension: 4096
- block 수: 32개
- 텍스트 인코더: T5 인코더
저자들은 해상도 범위가 17$\times$144$\times$256에서 121$\times$576$\times$1024까지인 텍스트 주석이 있는 대규모 이미지 및 동영상 데이터셋에서 11.5B VDiT 모델을 사전 학습시켰다.
2. VDiT with Camera Control (VDiT-CC)
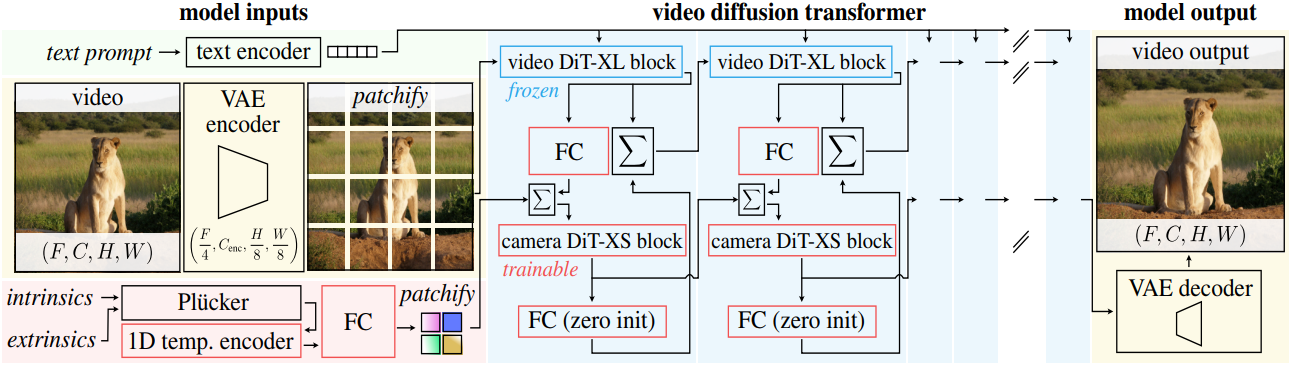
저자들은 카메라 제어를 위한 아키텍처를 구축하기 위해 VDiT 위에 ControlNet 컨디셔닝을 구현하였다. 6.5만 개의 (텍스트, 동영상, 카메라 궤적) triplet $(x_n, y_n, c_n)_{n=1}^N$로 구성된 RealEstate10k 데이터셋을 사용하고 카메라 정보를 모델에 입력하기 위한 새로운 모델 파라미터 세트를 학습시킨다. 카메라 궤적 $c \in \mathbb{R}^{f \times 25}$는 각 $f$번째 프레임 $x_f$에 대해 extrinsic $C_f \in \mathbb{R}^{4 \times 4}$와 intrinsic $K_f \in \mathbb{R}^{3 \times 3}$의 형태로 제공된다.
카메라 컨디셔닝
VD3D와 마찬가지로 Plücker 카메라 표현을 사용하는데, 이는 완전히 convolutional한 인코더를 통해 동영상 토큰과 동일한 차원과 해상도로 projection되어 카메라 토큰을 생성한다. 카메라 토큰은 hidden dimension이 128이고 4개의 attention head가 있는 일련의 DiT-XS block들로 처리된다. 카메라 정보를 VDiT의 동영상 토큰과 혼합하기 위해, 각 주요 DiT block 전에 더해진다. 또한, 동영상 토큰에서 카메라 토큰으로 cross-attention을 수행하는 것이 유용하다.
학습
VDiT backbone을 고정한 채로 rectified flow 목적 함수와, location이 0이고 scale이 1인 logit-normal noise distribution를 사용하여 새로운 파라미터를 학습시킨다. 10%의 카메라 dropout을 적용하여 classifier-free guidance (CFG)를 지원한다. 특히 VDiT-CC를 256$\times$256 해상도에서만 학습시킨다. 카메라 모션은 저주파 유형의 신호이고 VDiT backbone이 고정되어 있기 때문에 이러한 설계가 즉시 더 높은 해상도로 일반화된다. Inference하는 동안 각 timestep에서 CFG를 사용하여 텍스트 프롬프트와 카메라 임베딩을 입력한다.
Model behavior
강력한 VDiT 위에 구축된 이 모델은 이미 적절한 품질의 카메라 제어를 달성한다. 그러나 저하된 시각적 품질, 감소된 장면 모션, 때로는 카메라 제어가 무시되는 문제가 있다. 모델을 개선하기 위해 VDiT backbone을 분석하여 카메라 모션이 어떻게 모델링되고 표현되는지 이해한 다음 VDiT-CC의 실패 사례와 그러한 사례가 발생하는 곳을 확인하여 문제를 해결한다.
3. How is camera motion modeled by diffusion?
저자들은 카메라 모션이 사전 학습된 video diffusion model에 의해 어떻게 모델링되는지 분석하는 것으로 시작하였다. 카메라 포즈의 변화로 인해 유도된 모션이 저주파 유형의 신호라고 가정하고, denoising process의 여러 step에서 생성된 동영상의 motion spectral volume (MSV)을 조사하였다.
저자들은 80-step denoising을 사용하여 VDiT 모델로 200개의 다양한 동영상을 생성하고, 직접 4가지 카테고리로 주석을 달았다.
- 장면 모션만 있는 동영상
- 카메라 모션만 있는 동영상
- 장면 모션과 카메라 모션이 모두 있는 동영상
- 기타
생성하는 동안, 각 denoising step에서 denoise된 예측을 저장하고, MSV를 계산하기 위해 optical flow를 추정한다.
분석
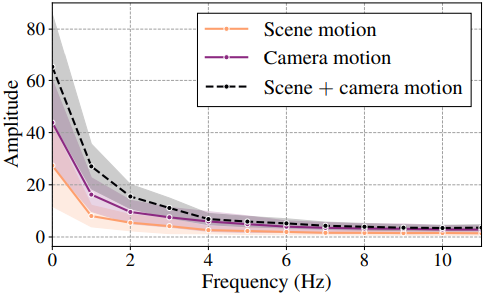
위 그림은 95% 신뢰 구간으로 카테고리에 따라 MSV를 시각화한 것이다. 저주파 성분의 경우 카메라 모션이 있는 동영상은 장면 모션만 있는 동영상보다 진폭이 더 높은 반면, 고주파 성분의 경우 유사한 특성을 보인다. 이는 카메라 모션이 저주파 유형의 신호라는 추측을 뒷받침한다.

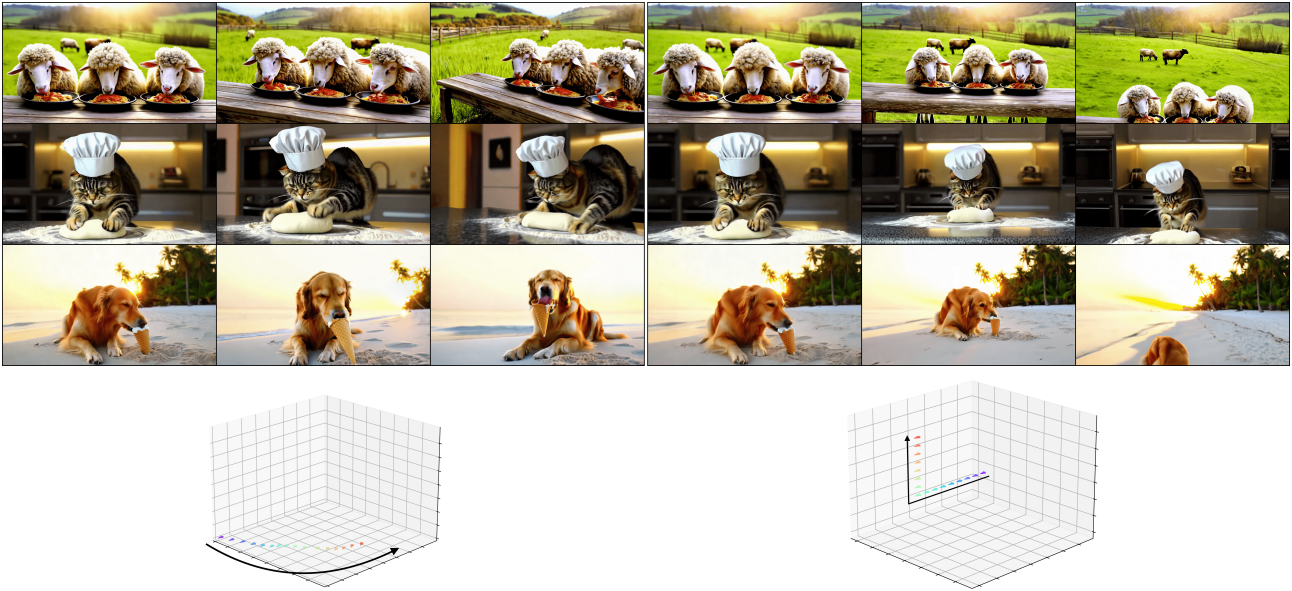
위 그림은 장면 모션과 카메라 모션이 모두 포함된 생성된 동영상의 예시이다. 카메라 모션은 $t=0.9$에 이미 완전히 생성되었음을 알 수 있다. 반면 피사체의 손 움직임과 같은 장면 모션 디테일은 $t=0.5$까지도 확정되지 않았다.
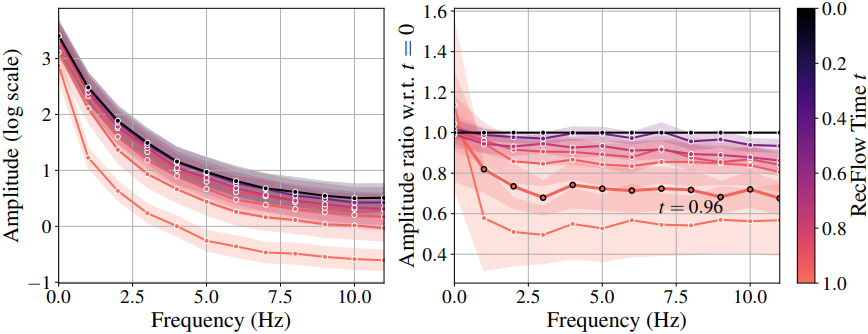
Video diffusion model은 정확히 언제 카메라 모션을 결정하는 것일까? 이 질문에 답하기 위해, 저자들은 다양한 timestep에 대한 MSV와 모든 모션이 생성된 마지막 timestep $t=0$에 대한 비율을 plot하고, denoising process 중에 다양한 유형의 모션이 시작되는 시점을 확인하였다. 위 그래프에서 볼 수 있듯이, 저주파 모션 성분은 $t=0.9$에서 약 84%까지 채워지는 반면, 고주파 성분은 $t=0.6$이 될 때까지 완전히 채워지지 않는다.
즉, denoising process에서 나중에 카메라를 제어하려는 시도가 불필요하며 조작 결과에 영향을 미치지 않는다는 것을 의미한다. 따라서, location이 0이고 scale이 1인 logit-normal noise distribution을 사용하는 대신 $[0.6, 1]$ 간격에서 location이 0.8이고 scale이 0.075인 분포를 사용하여 rectified flow 궤적의 초기 step을 커버한다.
저자들은 inference 시에 동일하게 $[0.6, 1]$ 간격에서 카메라 컨디셔닝을 적용했지만, 이는 불필요할 뿐만 아니라 장면 모션과 전반적인 시각적 품질에 해롭다는 것을 관찰하였다. 따라서 학습 시의 noise level과 테스트 시의 카메라 컨디셔닝 schedule을 모두 reverse diffusion 궤적의 처음 40%만 포함하도록 제한한다. 그 결과, FID와 FVD는 평균 14% 향상되고, 카메라 추적은 30% 향상되었으며, 전반적인 장면 모션도 향상되었다.
4. What does VDiT know about camera pose?
저자들은 동영상 모델이 표현 내에 카메라 신호에 대한 정보를 저장한다고 가정하고, 이를 조사하기 위해, RealEstate10k 데이터셋에서 카메라 extrinsic을 대상으로 VDiT base model의 linear probing을 수행하였다.
구체적으로, RealEstate10K에서 무작위 49프레임 동영상 1,000개를 가져와 8가지 noise level ($1/8, 2/8, \ldots, 1$)로 VDiT에 공급하고 모든 32개 DiT block에 대한 activation들을 추출한다. 그런 다음, 이를 900개의 학습 동영상과 100개의 테스트 동영상으로 분할하고, linear ridge regression model을 학습시켜 전체 시점 궤적에 대한 회전 pitch/yaw/roll 각도와 translation 벡터를 예측한다 (총 49$\times$6개의 값). 이를 통해 8$\times$32개의 학습된 모델이 생성된다.
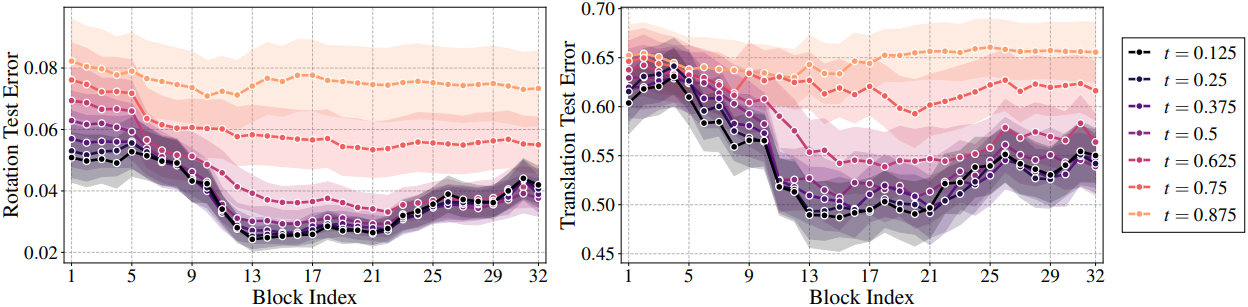
위 그래프는 100개 동영상의 테스트 동영상에 대한 rotation 및 정규화된 translation 오차이다. 놀랍게도 VDiT는 카메라 신호를 정확하게 예측한다. 지식의 품질은 9번째 block 주변에서 증가하고 13 ~ 21번째 block에서 최고치를 보인다. 이는 13번째 block의 카메라 정보가 그렇게 얽히지 않은 방식으로 저장되어 있기 때문에 모델이 그것을 사용하여 다른 표현을 구축하기 때문이며, 이 부분에서 카메라를 컨디셔닝하는 것은 위험하고 불필요하며 다른 visual feature를 방해한다.
따라서 처음 8개의 block에만 카메라를 컨디셔닝하고 나머지 24개의 block은 컨디셔닝하지 않는다. 이는 학습 가능한 파라미터의 양을 약 4배 줄이고 학습 속도를 약 15% 향상시킬 뿐만 아니라 시각적 품질을 약 10% 향상시킨다.
5. Mitigating training data limitations
In-the-wild 동영상에서 카메라 파라미터를 추정하는 것은 여전히 어려운 일이며, 주요 방법들은 동적 콘텐츠가 포함된 동영상을 처리할 때 자주 실패한다. 이러한 제한으로 인해 카메라 주석이 달린 데이터셋은 정적 장면에 크게 치우쳐 있으며, 특히 카메라 제어 동영상 모델을 학습하는 데 주로 사용되는 RealEstate10K에서 두드러진다. 이러한 데이터에 따라 fine-tuning된 모델은 카메라 위치 정보를 장면 역학을 억제하는 신호로 해석한다. 이러한 편향은 제약이 없는 2D 동영상 데이터에서 공동으로 학습할 때에도 지속되는데, 카메라 컨디셔닝 branch는 카메라 파라미터를 사용할 수 있을 때만 활성화되기 때문이며, 이는 RealEstate10K의 정적 장면에 대해서만 발생한다.

저자들은 이러한 근본적인 한계를 해결하기 위해 대안적인 접근 방식을 제안하였다. 동적 장면에 주석을 다는 대신, 고정 카메라로 촬영한 동적 장면이 포함된 2만 개의 다양한 동영상 컬렉션을 큐레이션한다. 고정된 카메라를 사용하면 카메라 위치를 본질적으로 알 수 있으므로 학습 중에 카메라 컨디셔닝을 계속 활성화할 수 있다. 이 접근 방식을 사용하면 모델을 동적 콘텐츠에 노출시키는 동시에 학습 중에도 카메라 컨디셔닝 branch를 활성 상태로 유지하여 시점 컨디셔닝과 장면의 정지를 구별하는 데 도움이 된다.
4DiM을 따라, 이 보조 데이터셋에서 metric depth estimator를 활용하여 RealEstate10K의 스케일 모호성을 제거한다. 이 간단하면서도 효과적인 데이터 큐레이션 전략은 RealEstate10K의 분포적 한계를 성공적으로 완화하여 손실된 장면 역학의 대부분을 복원하는 동시에 정확한 카메라 제어를 가증하게 한다.
6. Miscellaneous improvements
1D temporal camera encoder
VDiT-CC는 시간적으로 4배 압축된 latent space에서 동영상을 처리하며, 전체 해상도에 대한 카메라 파라미터를 통합하는 방법이 필요하다. 카메라 포즈를 latent 해상도와 일치하도록 단순하게 축소시킬 수 있지만, 이렇게 하면 작은 DiT-XS block이 압축된 카메라 정보를 처리해야 한다. 그 대신, 저자들은 각 픽셀에 대한 Plücker 좌표의 $F \times 6$ 시퀀스를 $(F//4) \times 32$ 표현으로 변환하는 causal 1D convolution들의 시퀀스를 사용하였다.
텍스트와 카메라 guidance를 분리
텍스트와 카메라 신호는 그 특성상 서로 다른 guidance 가중치가 필요하므로 classifier-free guidance (CFG)를 분리한다.
\[\begin{equation} \hat{s} (x \vert y, c) = (1 + w_y + w_c) s_\theta (x \vert y, c) - w_y s_\theta (x \vert c) - w_c s_\theta (x \vert y) \end{equation}\]($\hat{s}$는 최종 업데이트 방향, \(s_\theta\)는 모델이 예측한 업데이트 방향, $y$는 텍스트 조건, $c$는 카메라 조건, $w_y$와 $w_c$는 CFG 가중치)
피드백이 있는 ControlNet
최근 카메라 제어 방법에서 사용되는 기존 ControlNet은 메인 branch에 액세스하지 않고 컨디셔닝 신호만 처리한다. 반면, 저자들은 transformer 계산에서 동영상 토큰에서 카메라 토큰으로의 cross-attention을 추가하여 더 나은 카메라 표현이 가능하도록 하였다. 이 수정은 메인 branch가 카메라 처리 branch에 제공하는 피드백 메커니즘으로 작동한다.
카메라 branch에서 컨텍스트 제거
카메라 DiT-XS block에서 컨텍스트 정보(텍스트 프롬프트, 해상도 등)에 cross-attention을 적용하면 카메라 표현과 컨텍스트 임베딩의 유해한 간섭으로 인해 시각적 품질이 저하되고 카메라 제어 능력이 저하된다. 따라서 저자들은 카메라 branch에서 컨텍스트를 제거하였다.
Experiments
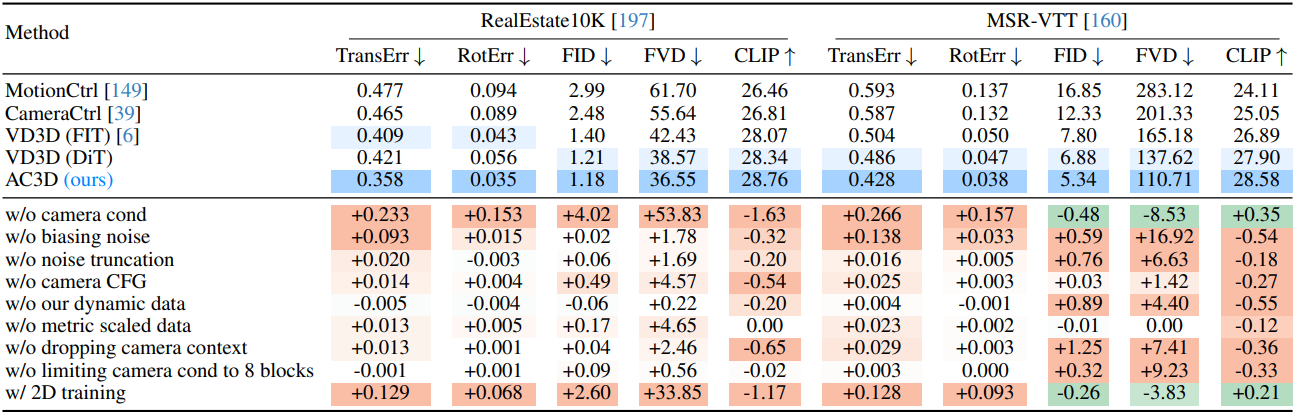
다음은 다른 방법들과의 성능 비교 및 ablation study 결과를 나타낸 표이다.
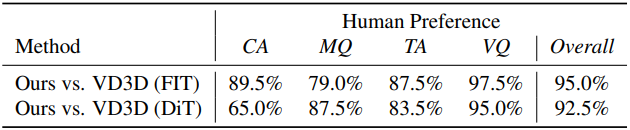
다음은 user study 결과이다.