[논문리뷰] 4D-Rotor Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes
SIGGRAPH 2024. [Paper]
Yuanxing Duan, Fangyin Wei, Qiyu Dai, Yuhang He, Wenzheng Chen, Baoquan Chen
Peking University | Princeton University | NVIDIA | National Key Lab of General AI, China
5 Feb 2024

Introduction
2D 이미지에서 3D 장면을 재구성하고 새로운 시점에서 그 모습을 합성하는 Novel View Synthesis(NVS)는 컴퓨터 비전과 그래픽스 분야의 오랜 목표였다. 이 task는 두 가지 장면 유형, 즉 모든 이미지에 객체가 여전히 있는 정적 장면과 장면 내용이 시간적 변화를 나타내는 동적 장면으로 나뉜다. 전자는 최근 상당한 진전을 보였지만, 후자는 시간적 차원과 다양한 모션 패턴으로 인해 발생하는 복잡성으로 인해 동적 장면에 대한 효율적이고 정확한 NVS는 여전히 어려운 과제로 남아 있다.
동적 NVS로 인해 발생하는 문제를 해결하기 위해 다양한 방법이 제안되었다. 여러 방법들은 3D 장면과 그 역학을 공동으로 모델링하였다. 그러나 이러한 방법은 고도로 얽힌 시공간적 차원에 의한 복잡성으로 인해 NVS 렌더링의 세밀한 디테일을 보존하는 데 종종 부족하다. 대안으로, 많은 기존 기술은 정적인 표준 공간을 학습한 다음 시간적 변화를 설명하기 위해 deformation field를 예측하여 동적 장면을 분리하였다. 그럼에도 불구하고 이 패러다임은 물체가 갑자기 나타나거나 사라지는 등 복잡한 역학을 포착하는 데 어려움을 겪는다. 더 중요한 것은 동적 NVS에서 널리 사용되는 방법은 대부분 수백만 개의 광선에 대한 dense한 샘플링이 필요한 볼륨 렌더링을 기반으로 한다는 것이다. 결과적으로 이러한 방법은 일반적으로 정적 장면에 대해서도 실시간 렌더링 속도를 지원할 수 없다.
최근 3D Gaussian Splatting(3DGS)이 정적 장면의 효율적인 NVS를 위한 강력한 도구로 등장했다. 3D Gaussian 타원체로 장면을 명시적으로 모델링하고 빠른 rasterization 기술을 사용하여 실시간으로 사진처럼 사실적인 NVS를 구현하였다. 이에 영감을 받아 저자들은 Gaussian을 3D에서 4D로 끌어올리고 보다 도전적인 동적 장면에 대해 NVS를 가능하게 하는 새로운 시공간 표현을 제공할 것을 제안하였다.
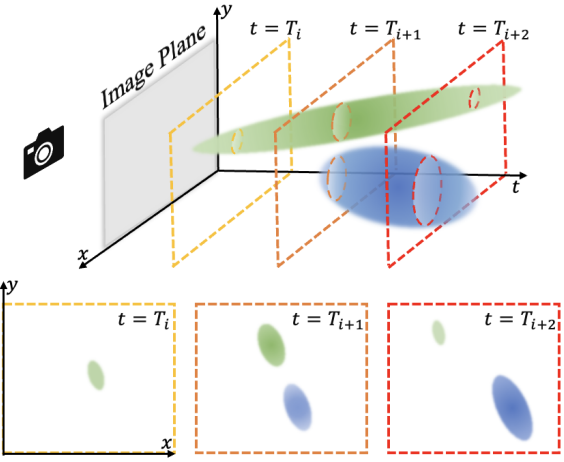
저자들의 주요 관찰은 각 타임스탬프의 3D 장면 역학이 서로 다른 시간 쿼리로 분할된 4D 시공간 Gaussian 타원체로 볼 수 있다는 것이다. 위 그림은 단순화된 $XYT$ 케이스를 보여준다. 시간 $T_i$에서 2D $XY$ 공간의 역학은 3D $XYT$ Gaussian을 구축하고 $t = T_i$ 평면으로 슬라이싱하는 것과 동일하다. 마찬가지로 3D Gaussian을 4D $XYZT$ 공간으로 확장하여 동적인 3D 장면을 모델링한다. 시간적으로 분할된 4D Gaussian은 빠른 rasterization을 통해 2D 화면에 원활하게 투영할 수 있는 3D Gaussian을 구성하며, 3DGS의 절묘한 렌더링 효과와 고속 특성을 모두 상속한다. 더욱이, 시간 차원에서 prune-split 메커니즘을 확장하면 4D Gaussian이 갑작스러운 출현이나 소멸을 포함한 복잡한 역학을 표현하는 데 특히 적합해진다.
3D Gaussian을 4D 공간으로 끌어올리는 것은 4D rotation, 슬라이싱, 시공간 공동 최적화 체계 설계 등 엄청난 과제가 존재한다. 저자들은 시공간적으로 분리 가능한 4D rotation을 표현하기 위해 4D rotor를 선택했다. 특히 rotor 표현은 3D rotation과 4D rotation을 모두 수용한다. 시간 차원이 0으로 설정되면 quaternion과 동일해지며 3D rotation도 나타낼 수 있다. 이러한 적응성은 동적 장면과 정적 장면을 모두 모델링할 수 있는 유연성을 부여한다. 즉, 4DRotorGS는 3DGS의 일반화 가능한 형태이다. 시간 차원을 없애면 4DRotorGS가 3DGS로 줄어든다.
저자들은 3DGS의 최적화 전략을 강화하고 동적 재구성을 안정화하고 개선하기 위해 두 가지 새로운 정규화 항을 도입하였다. 먼저 Gaussian의 불투명도를 1 또는 0으로 밀어내는 entropy loss를 제안하였다. 이는 실험에서 floater를 제거하는 데 효과적인 것으로 입증되었다. 저자들은 Gaussian point의 움직임을 정규화하고 보다 일관된 역학 재구성을 생성하기 위해 새로운 4D consistency loss를 추가로 도입했다. 실험에 따르면 두 항 모두 렌더링 품질이 눈에 띄게 향상되는 것으로 나타났다.
기존 Gaussian 기반 방법은 대부분 PyTorch를 기반으로 하지만 저자들은 빠른 학습과 inference 속도를 위해 고도로 최적화된 CUDA 프레임워크를 추가로 개발하였다. 이 프레임워크는 RTX 4090 GPU에서 583FPS, RTX 3090 GPU에서 277FPS로 1352$\times$1014 동영상 렌더링을 지원한다.
Method
1. 4D Gaussian Splatting
Rotor-Based 4D Gaussian Representation
3D Gaussian과 유사하게 4D Gaussian은 4D 중심 위치 $\mu_\textrm{4D} = (\mu_x, \mu_y, \mu_z, \mu_t)$와 4D 공분산 행렬 $\Sigma_\textrm{4D}$로 표현될 수 있다.
\[\begin{equation} G_\textrm{4D} (x) = \exp (-\frac{1}{2} (x - \mu_{4D})^\top \Sigma_{4D}^{-1} (x - \mu_{4D})) \end{equation}\]공분산 $\Sigma_\textrm{4D}$는 다음과 같이 4D scaling \(\mathbf{S}_\textrm{4D}\)와 4D rotation \(\mathbf{R}_\textrm{4D}\)로 추가로 인수분해될 수 있다.
\[\begin{equation} \Sigma_\textrm{4D} = \mathbf{R}_\textrm{4D} \mathbf{S}_\textrm{4D} \mathbf{S}_\textrm{4D}^\top \mathbf{R}_\textrm{4D}^\top \end{equation}\]\(\mathbf{S}_\textrm{4D} = \textrm{diag} (s_x, s_y, s_z, s_t)\)로 모델링하는 것은 간단하지만 \(\mathbf{R}_\textrm{4D}\)에 대한 적절한 4D rotation 표현을 찾는 것은 어려운 문제이다.
고차원 벡터의 rotation은 rotor를 사용하여 설명할 수 있다. 저자들은 4D rotation을 특성화하기 위해 4D rotor를 도입하였다. 4D rotor $\mathbf{r}$은 일련의 basis를 기반으로 8개의 성분으로 구성된다.
\[\begin{aligned} \mathbf{r} = &\; s + b_{01} \mathbf{e}_{01} + b_{02} \mathbf{e}_{02} + b_{03} \mathbf{e}_{03} + b_{12} \mathbf{e}_{12} \\ & + b_{13} \mathbf{e}_{13} + b_{23} \mathbf{e}_{23} + p \mathbf{e}_{0123} \end{aligned}\]여기서 \(\mathbf{e}_{0123} = \mathbf{e}_0 \wedge \mathbf{e}_1 \wedge \mathbf{e}_2 \wedge \mathbf{e}_3\)이고 \(\mathbf{e}_{ij} = \mathbf{e}_i \wedge \mathbf{e}_j\)는 4D 유클리드 공간에서 orthonormal basis를 형성하는 4D 축 \(\mathbf{e}_i\) 사이의 외적이다. 따라서 4D rotation은 8개의 계수 $(s, b_{01}, b_{02}, b_{03}, b_{12}, b_{13}, b_{23}, p)$에 의해 결정될 수 있다.
Quaternion과 유사하게 rotor $\mathbf{r}$은 적절한 정규화 함수 \(\mathcal{F}_\textrm{norm}\)과 rotor-matrix 매핑 함수 \(\mathcal{F}_\textrm{map}\)을 사용하여 4D rotation 행렬 $\mathbf{R}_\textrm{4D}$로 변환될 수도 있다.
\[\begin{equation} \mathbf{R}_\textrm{4D} = \mathcal{F}_\textrm{map} (\mathcal{F}_\textrm{norm} (\mathbf{r})) \end{equation}\]Rotor 기반 4D Gaussian은 잘 정의되고 해석 가능한 rotation 표현을 제공한다. 처음 4개 성분은 3D rotation을 인코딩하고 마지막 4개 성분은 시공간 rotation, 즉 공간 변환을 정의한다. 특히, 마지막 4개 성분을 0으로 설정하면 $\mathbf{r}$이 3D rotation을 위한 quaternion이 되어 프레임워크가 정적 장면과 동적 장면을 모두 모델링할 수 있다. 아래 그림은 정적인 3D 장면의 결과가 원본 3DGS의 결과와 일치하는 예를 보여준다.

RealTime4DGS도 4D Gaussian을 사용하여 동적 장면을 모델링한다. 그러나 두 개의 얽힌 quaternion으로 4D rotation을 나타낸다. 결과적으로 시공간적 rotation이 밀접하게 결합되어 있으며 정적 3D 장면을 모델링하기 위해 최적화하는 동안 이 rotation 표현을 제한하고 정규화하는 방법이 불분명하다.
Temporally-Sliced 4D Gaussians Splatting
이제 4D Gaussian을 3D 공간으로 분할하는 방법을 설명한다. \(\Sigma_\textrm{4D}\)와 그 역 \(\Sigma_\textrm{4D}^{-1}\)가 모두 대칭 행렬이라는 점을 고려하여 다음과 같이 정의한다.
\[\begin{equation} \Sigma_\textrm{4D} = \begin{bmatrix} \mathbf{U} & \mathbf{V} \\ \mathbf{V}^\top & \mathbf{W} \end{bmatrix}, \quad \Sigma_\textrm{4D}^{-1} = \begin{bmatrix} \mathbf{A} & \mathbf{M} \\ \mathbf{M}^\top & \mathbf{Z} \end{bmatrix} \end{equation}\]여기서 $\mathbf{U}$와 $\mathbf{A}$는 모두 3$\times$3 행렬이다. 그런 다음 시간 $t$가 주어지면 투영된 3D Gaussian은 다음과 같이 얻어진다.
\[\begin{aligned} G_\textrm{3D} (\mathbf{x}, t) &= \exp (-\frac{1}{2} \lambda (t - \mu_t)^2) \exp (-\frac{1}{2} (\mathbf{x} - \mu(t))^\top \Sigma_{3D}^{-1} (\mathbf{x} - \mu (t))) \\ \lambda &= \mathbf{W}^{-1} \\ \Sigma_\textrm{3D} &= \mathbf{A}^{-1} = \mathbf{U} - \frac{\mathbf{V} \mathbf{V}^\top}{\mathbf{W}} \\ \mu (t) &= (\mu_x, \mu_y, \mu_z)^\top + (t - \mu_t) \frac{\mathbf{V}}{\mathbf{W}} \end{aligned}\]원래 3DGS의 식과 위 식의 슬라이싱된 3D Gaussian은 시간적 감쇠 항 $\exp (-\frac{1}{2} \lambda (t - \mu_t)^2)$을 포함한다. $t$가 지나감에 따라 $t$가 시간적 위치 $µ_t$에 충분히 가까워지면 Gaussian point가 나타나며 점점 커진다. $t = \mu_t$일 때 최대 불투명도에 도달한다. 그 후, 3D Gaussian은 $t$가 $\mu_t$에서 충분히 멀어져 사라질 때까지 밀도가 점차 줄어든다. 4D Gaussian은 시간적 위치와 scaling factor를 제어함으로써 갑자기 나타나거나 사라지는 모션과 같은 까다로운 역학을 표현할 수 있다. 렌더링하는 동안 현재 시간에서 너무 멀리 있는 점을 필터링한다. 여기서 visibility의 threshold $\frac{1}{2} \lambda (t-\mu_t)^2$은 경험적으로 16으로 설정된다.
슬라이싱된 3D Gaussian은 중앙 위치 $(\mu_x, \mu_y, \mu_z)^\top$에 $(t − \mu_t) \mathbf{V} / \mathbf{W}$라는 새로운 모션 항을 더한다. 이론적으로 3D Gaussian의 선형 움직임은 4D 슬라이싱 연산에서 나타난다. 저자들은 작은 시간 간격에서 모든 운동은 선형 운동으로 근사화될 수 있으며, 더 복잡한 비선형 경우는 여러 Gaussian의 조합으로 표현될 수 있다고 가정하였다. 또한 $\mathbf{V}/\mathbf{W}$는 현재 타임스탬프의 모션 속도를 나타낸다. 따라서 이 프레임워크를 사용하여 장면을 모델링하면 무료로 속도장을 얻을 수 있다.
마지막으로 3DGS를 따라 슬라이싱된 3D Gaussian을 깊이 순서로 2D 이미지 평면에 투영하고 빠르고 미분 가능한 rasterization을 수행하여 최종 이미지를 얻는다. 이를 통해 고성능 CUDA 프레임워크에서 rotor 표현과 슬라이싱을 구현하고 PyTorch 구현에 비해 훨씬 더 빠른 렌더링 속도를 달성하였다.
2. Optimization Schema
3D Gaussian을 4D 공간으로 끌어올릴 때 증가된 차원으로 인해 Gaussian point의 자유도가 확장된다. 따라서 학습 프로세스를 안정화하는 데 도움이 되는 두 가지 정규화 항인 entropy loss와 4D consistency loss를 도입한다.
Entropy Loss
NeRF와 유사하게 각 Gaussian point에는 학습 가능한 불투명도 항 $o_i$가 있으며 볼륨 렌더링 공식이 적용되어 최종 색상을 합성한다. 이상적으로 Gaussian point는 물체 표면에 가까워야 하며 대부분의 경우 불투명도는 1에 가까워야 한다. 따라서 entropy loss를 추가하여 불투명도가 1에 가까워지거나 0에 가까워지도록 권장하고 기본적으로 불투명도가 거의 0에 가까운 Gaussian은 학습 중에 제거된다.
\[\begin{equation} L_\textrm{entropy} = \frac{1}{N} \sum_{i=1}^N - o_i \log o_i \end{equation}\]\(L_\textrm{entropy}\)는 Gaussian point를 압축하고 floater를 필터링하는 데 도움이 된다. 이는 sparse한 view로 학습할 때 매우 유용하다.
4D Consistency Loss
직관적으로 4D 공간에서 근처의 Gaussian은 유사한 모션을 가져야 한다. 4D consistency loss를 추가하여 4D Gaussian point들을 더욱 정규화한다. 주어진 시간 $t$에서 4D Gaussian을 슬라이싱할 때 속도 항 $\mathbf{s}$가 도출된다. 따라서 $i$번째 Gaussian point가 주어지면 이웃 공간 $\Omega_i$에서 가장 가까운 $K$개의 4D 포인트를 수집하고 해당 모션을 일관되게 정규화한다.
\[\begin{equation} L_\textrm{consisten4D} = \frac{1}{N} \sum_{i=1}^N \bigg\| \mathbf{s}_i - \frac{1}{K} \sum_{j \in \Omega_i} \mathbf{s}_j \bigg\| \end{equation}\]4D Gaussian의 경우 4D 거리는 3D 거리보다 점 유사성에 대한 더 나은 metric이다. 왜냐하면 3D에서 이웃한 점이 반드시 동일한 동작을 따르지는 않기 때문이다. 4D nearest neighbors 계산은 4D 표현에서 고유하고 자연스럽게 활성화되며 deformation 기반 방법으로는 활용할 수 없다. 저자들은 상응하는 공간적, 시간적 장면 스케일로 나누어 각 차원의 다양한 스케일의 균형을 맞췄다.
Total Loss
원본 3DGS를 따라 렌더링된 이미지와 실제 이미지 사이에 $L_1$ loss와 SSIM loss를 추가한다. 최종 loss는 다음과 같이 정의된다.
\[\begin{equation} L = (1 - \lambda_1) L_1 + \lambda_1 L_\textrm{ssim} + \lambda_2 L_\textrm{entropy} + \lambda_3 L_\textrm{consisten4D} \end{equation}\]Optimization Framework
저자들은 두 가지 버전을 구현하였다. 하나는 빠른 개발을 위해 PyTorch를 사용한 버전이고 다른 하나는 빠른 학습 및 inference를 위해 C++와 CUDA에 고도로 최적화된 버전아다. PyTorch 버전과 비교할 때 CUDA 가속 버전을 사용하면 NVIDIA RTX 4090 GPU 1개에서 1352$\times$1014 해상도에 대하여 583FPS로 렌더링할 수 있다. 또한 CUDA 프레임워크는 학습 속도를 16.6배까지 가속화한다. Baseline과의 벤치마킹을 위해 저자들은 RTX 3090 GPU에서 프레임워크를 테스트하고 현재 SOTA(114FPS)보다 훨씬 뛰어난 277FPS를 달성했다.
Experiments
- 데이터셋: Plenoptic Video Dataset, D-NeRF Dataset
- 구현 디테일
- 초기화
- mean: 4D bounding box에서 100,000개의 점을 균일하게 샘플링. Plenoptic 데이터셋의 경우 COLMAP reconstruction으로 초기화
- 3D scale: 가장 가까운 이웃까지의 거리로 설정.
- rotor: 정적 항등 변환과 동일한 $(1, 0, 0, 0, 0, 0, 0, 0)$으로 초기화
- 학습
- optimizer: Adam
- Plenoptic
- step: 20,000, batch size: 3
- $\lambda_1$ = 0.2, $\lambda_2$ = 0.01, $\lambda_3$ = 0.05, $K$ = 8
- densification gradient threshold: $5 \times 10^{-5}$
- D-NeRF
- step: 30,000, batch size: 2
- $\lambda_1$ = 0.2, $\lambda_2$ = 0, $\lambda_3$ = 0.05, $K$ = 8
- densification gradient threshold: $2 \times 10^{-4}$
- 초기화
1. Results
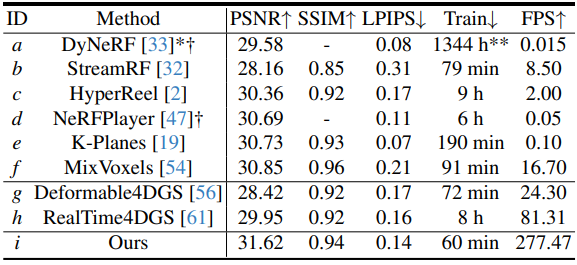
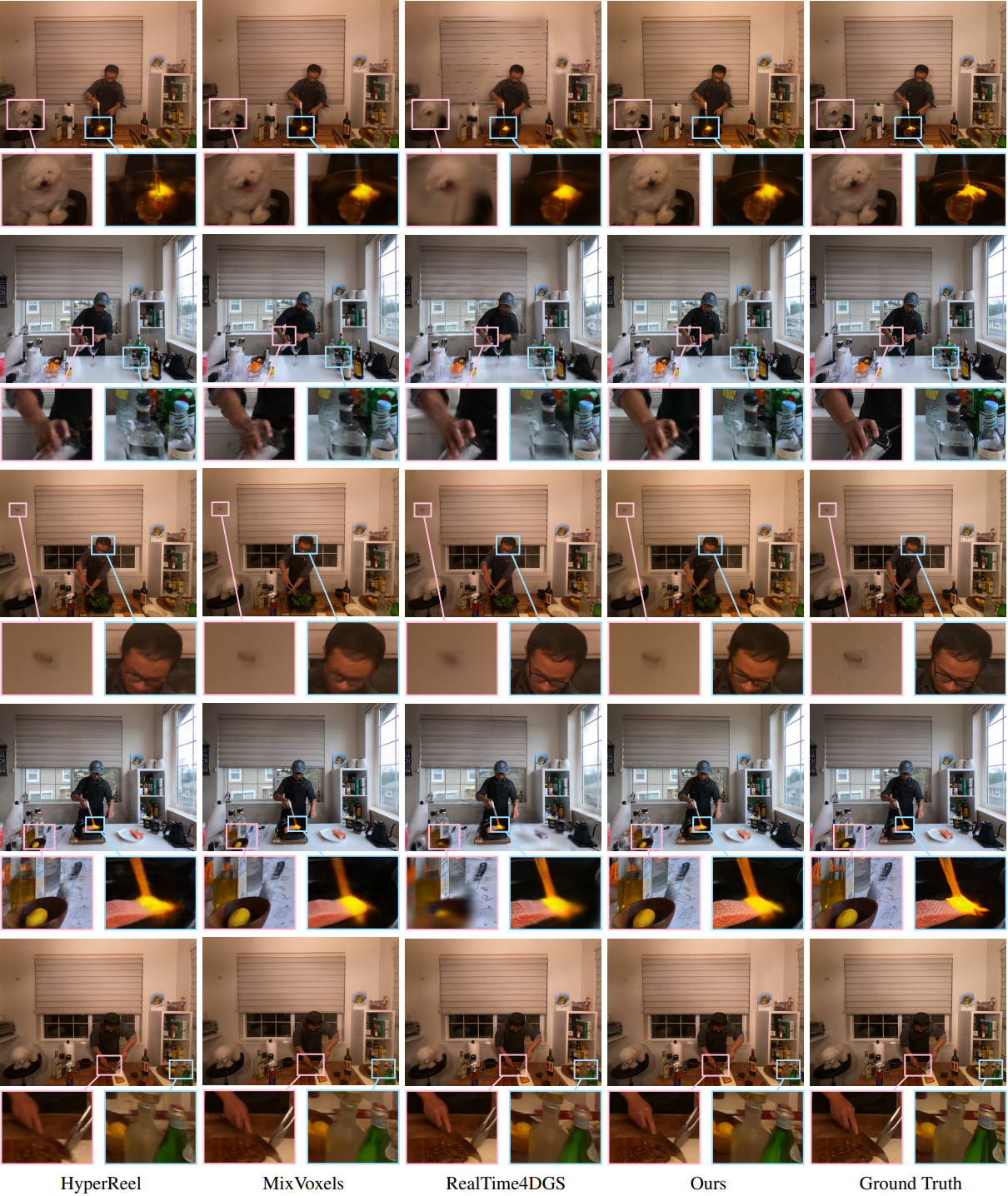
Plenoptic Video Dataset
다음은 Plenoptic 데이터셋에서 최신 NeRF 기반 및 Gaussian 기반 방법들과 비교한 결과이다.
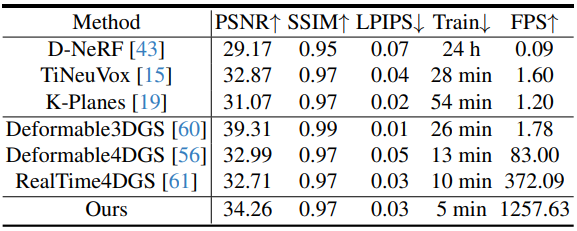
Evaluation on D-NeRF Dataset
다음은 D-NeRF 데이터셋에서 최신 NeRF 기반 및 Gaussian 기반 방법들과 비교한 결과이다.

2. Ablation Studies
다음은 D-NeRF 데이터셋에서의 ablation study 결과이다.


다음은 optical flow를 시각화한 것이다.
