[논문리뷰] Bridging Diffusion Models and 3D Representations: A 3D Consistent Super-Resolution Framework
ICCV 2025. [Paper] [Page] [Github]
Yi-Ting Chen, Ting-Hsuan Liao, Pengsheng Guo, Alexander Schwing, Jia-Bin Huang
University of Maryland College Park | Carnegie Mellon University | University of Illinois at Urbana-Champaign
6 Aug 2025

Introduction
3D Gaussian Splatting (3DGS)은 효과적임에도 불구하고, 입력 카메라 뷰의 공간 해상도에 본질적으로 제약을 받아, 세부 디테일이 부족한 합성 이미지가 생성되는 경우가 많다. 본 논문에서는 diffusion model의 힘을 활용하여 3DGS의 해상도 제약을 해결한다. 구체적으로, 통합 3DGS 표현을 통해 novel view synthesis (NVS)에서 멀티뷰 일관성을 유지하면서 고품질 디테일 생성을 위해 diffusion model을 활용한다. 이 접근법은 여러 시점에 걸쳐 구조적 일관성을 유지하면서 고해상도 렌더링을 향상시켜, 기존 super-resolution (SR) 및 NVS의 한계를 효과적으로 해결한다.
Method
본 논문에서는 diffusion 기반 2D super-resolution을 활용하여 다양한 시점에서 3D 일관성을 향상시키는 3DGS 기반 super-resolution 프레임워크인 3DSR을 제안하였다. 본 프레임워크에서 사용되는 diffusion 기반 SR 방법은 image super-resolution (ISR) 또는 video super-resolution (VSR)에 국한되지 않으므로, 3DSR은 향후 이 분야의 발전으로부터 이점을 얻을 수 있다. SuperGaussian과 같은 VSR 기반 방법과 비교했을 때, 3DSR은 동영상 모델을 fine-tuning하지 않고도 3D 일관성을 더욱 명확하게 향상시킨다.
1. Proposed Framework
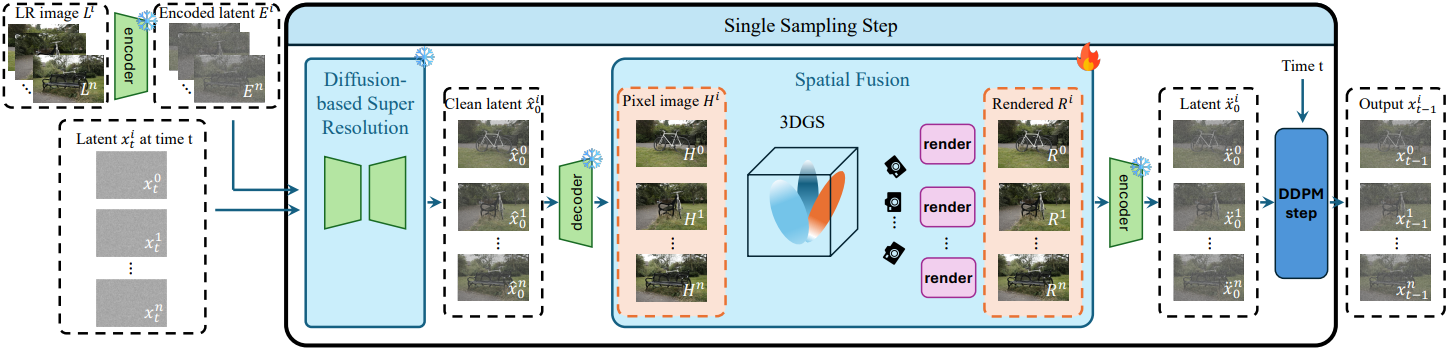
본 접근법에서는 인코더, 디코더, diffusion model은 고정된 상태로 유지되고, 3D 표현만 최적화된다. 특히, 3D 표현은 유연하며 NeRF, 3DGS, 또는 3D 장면 정보를 효과적으로 인코딩하는 다른 표현으로 인스턴스화될 수 있다.
저해상도(LR) 입력 이미지 집합 \(\{L^i\}_{i=0}^n\)과 해당 카메라 포즈 \(\{P^i\}_{i=0}^n\)이 주어졌을 때, 본 논문의 목표는 고품질 3D 장면을 재구성하는 것이다. 이 LR 이미지는 3D 표현 $\Theta$를 학습시키는 입력으로 사용되어 사전 학습된 LR 모델을 생성한다. 또한, LR 이미지는 인코더 $\mathcal{E}(\cdot)$에 의해 latent space 표현 $E^i$로 인코딩되며, 이는 diffusion 기반 SR 모델과 디코더 $\mathcal{D}(\cdot)$의 컨디셔닝 신호 역할을 한다. 이를 통해 출력이 원래 LR에 충실하도록 효과적으로 유도된다.
초기 샘플링 단계 $t$에서, 무작위로 샘플링된 noise latent 집합 $x_t^i$가 LR 이미지 latent $E^i$와 함께 diffusion 기반 SR 모델의 입력으로 초기화된다. 그런 다음, 모델은 다음 식을 사용하여 깨끗한 이미지 latent \(\hat{x}_0^i\)를 추정한다.
\[\begin{equation} \hat{x}_0^i = \frac{1}{\sqrt{\vphantom{1} \bar{\alpha}_t}} (x_t^i - \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta (x_t^i, t, E^i)) \end{equation}\]이렇게 추정된 latent는 이후 이미지 공간으로 디코딩되어 중간 고해상도 이미지 $H^i$를 생성한다.
다양한 시점에서 3D 일관성을 유지하기 위해, $\Theta$의 공간적으로 일관된 표현을 생성하는 기능을 활용한다. 추정된 고해상도 이미지 $H^i$는 3D 장면 표현 $\Theta$의 학습 데이터로 사용되어, 주어진 포즈의 고해상도 이미지 $\Theta(P^i) = R^i$를 동일한 시점에서 렌더링할 수 있도록 한다. 이 과정은 SR 출력을 정규화하여 여러 시점에서 세부적인 디테일이 구조적으로 정렬되도록 한다.
3D 일관된 고해상도 렌더링 $R^i$는 latent space로 재인코딩된다.
\[\begin{equation} \ddot{x}_0^i = \mathcal{E}(R^i) \end{equation}\]초기 추정값 \(\hat{x}_0^i\)과 비교했을 때, 업데이트된 latent \(\ddot{x}_0^i\)는 멀티뷰 일관성을 더 잘 유지한다. 다음 식을 사용하여 \(\ddot{x}_0^i\)을 현재 latent $x_t^i$와 통합하여 denoising process를 개선하고 다음 iteration에서 개선된 latent $x_{t-1}^i$을 얻을 수 있다.
\[\begin{equation} x_{t-1}^i = \sqrt{\alpha_{t-1}} \ddot{x}_0^i + \sqrt{1 - \alpha_{t-1} - \sigma_t^2} \epsilon_\theta (x_t^i, t) + \sigma_t \epsilon_t \end{equation}\]전체 알고리즘은 다음과 같다.

2. Training Objective
3DGS를 최적화하기 위해 서브샘플링 기반 정규화 전략을 사용한다. 이 접근법은 렌더링된 이미지 $R^i$를 저해상도 입력 $L^i$의 해상도에 맞춰 서브샘플링하여 \(R_\textrm{lr}^i\)를 생성함으로써 고해상도 디테일의 불일치를 완화한다. 이를 통해 렌더링된 이미지와 입력 이미지 간의 정렬이 촉진되어 렌더링 최적화 과정에서 전반적인 일관성이 향상된다.
전체 loss function은 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{hr} (H^i, R^i) + \lambda \mathcal{L}_\textrm{lr} (L^i, R_\textrm{lr}^i) \end{equation}\]\(\mathcal{L}_\textrm{hr}\)과 \(\mathcal{L}_\textrm{lr}\) 모두 \(\mathcal{L}_1\) loss와 D-SSIM loss의 조합으로 구성된다.
\[\begin{equation} \mathcal{L}_\alpha = (1 - \delta) \mathcal{L}_1^\alpha + \delta \mathcal{L}_\textrm{D-SSIM}^\alpha, \quad \alpha \in \{\textrm{hr}, \textrm{lr}\} \end{equation}\]Experiments
- 데이터셋: MipNeRF360, LLFF
- 구현 디테일
- SR 모델: StableSR-Turbo
- diffusion step: 4
- 각 diffusion step마다 5,000 iteration
- $\lambda = 1$, $\delta = 0.2$
- GPU: NVIDIA A6000 (49GB)
다음은 LLFF에서의 비교 결과이다. (8배 다운샘플링 후 4배 업샘플링)


다음은 LLFF에서의 비교 결과이다. (그림은 16배 다운샘플링 후 4배 업샘플링, 표는 8배 다운샘플링 후 4배 업샘플링)

