[논문리뷰] 3D Highlighter: Localizing Regions on 3D Shapes via Text Descriptions
CVPR 2023. [Paper] [Page] [Dataset]
Dale Decatur, Itai Lang, Rana Hanocka
University of Chicago
21 Dec 2022

Introduction
3D mesh에서 영역의 semantic localization은 컴퓨터 그래픽과 광범위한 응용 분야에서 중요한 문제이다. 이러한 애플리케이션 중 하나는 semantic 정보를 3D 모델링 프로세스에 통합하는 것이다. 이 task의 특히 어려운 측면은 3D 형상 신호가 분할을 수행하기에 불충분할 때 나타난다.
본 논문은 3D Highlighter라는 텍스트 설명만으로 모양에 세분화된 semantic 영역을 자동으로 위치 지정하는 방법을 제안한다. 본 논문의 시스템은 텍스트 프롬프트를 맥락화하고 네트워크 예측 확률을 사용하여 해당 모양 영역을 하이라이트한다. 텍스트만 사용하여 사용자는 모양의 영역을 의미론적으로 식별할 수 있다. 시스템은 mesh를 입력으로 받아 3D 모델링 도구와 호환되도록 한다.
이 하이라이트 task에는 객체 수준과 부분 수준의 이해가 모두 필요하다. 3D Highlighter는 램프 위의 모자와 같이 3D 모양에서 관련 없어 보이는 개념을 어디에 배치할지 추론하는 능력을 보여준다. 본 논문의 시스템은 모양에 기하학적으로 없는 속성을 localize하며 이를 hallucinated highlighting이라고 한다. 부품의 전체 형상 컨텍스트를 이해하는 것은 현저한 기하학적 특징에 의존하는 경우에도 어렵다.
지정된 텍스트에 따라 주어진 3D 모양을 색칠하는 데 사용되는 확률을 생성하기 위해 신경망의 가중치를 최적화한다. 사전 학습된 비전-언어 모델 (CLIP)을 활용하여 텍스트 지정 영역으로 최적화를 가이드한다. 이 최적화 공식은 유연하여 3D 데이터셋, 3D 주석, 3D 사전 학습이 필요하지 않다. 시스템은 특정 클래스 집합에 구속되지 않으며 두드러진 기하학적 특징으로 정의된 객체 부분에 제한되지 않는다.
부품 선택을 mesh 표면에 대한 neural field로 인코딩한다. 네트워크는 표면의 각 지점을 텍스트 지정 영역에 속하는 확률로 매핑하는 방법을 학습한다. 추론된 확률을 메시 표면의 시각적 속성으로 변환하여 렌더링하고 시각적으로 이해할 수 있다. 네트워크 예측 확률은 하이라이트 색상을 mesh에 혼합하는 soft-selection 연산자 역할을 한다. 네트워크 가중치는 하이라이트된 mesh의 2D 렌더링의 CLIP 임베딩이 지정된 텍스트를 준수하도록 권장하여 업데이트된다. 결과적으로 네트워크는 텍스트 프롬프트를 준수하기 위해 객체를 분할하는 방법을 암시적으로 학습한다.
본 논문은 3D Highlighter의 성공에 핵심적인 몇 가지 디자인을 선택하였다. 네트워크는 메시를 직접 색칠하지 않는다. 오히려 mesh에서 색상을 혼합하는 데 사용되는 텍스트 지정 하이라이트 내부에 있을 확률을 예측한다. 포인트가 하이라이트될 확률이 약 50%가 되도록 네트워크가 초기화되어 하이라이트와 배경색 중간에 알베도가 있는 mesh가 생성된다. 최적화 중에 하이라이트 색상의 상대적 혼합 가중치는 하이라이트 확률과 직접적으로 일치한다. 이 혼합을 통해 네트워크는 대상 영역의 텍스트 사양에 따라 분할 확률을 자연스럽고 원활하게 늘리거나 줄일 수 있다.
Method

본 논문의 방법은 위 그림에 나와 있다. 시스템에 대한 입력은 mesh $M$이며 정점 $V \in \mathbb{R}^{n \times 3}$, 면 \(F \in \{1, \ldots, n\}^{m \times 3}\), 텍스트 설명 $T$로 표시된다. Neural highlighter라고 하는 신경망은 정점 위치 $v \in V$를 텍스트 지정 영역에 속하는 확률 $p$에 매핑하도록 최적화되어 있다. Mesh의 각 정점은 하이라이트 색상과 회색 배경 색상 사이의 확률 가중치 혼합에 따라 색상이 지정된다. 결과로 하이라이트된 mesh $M’$은 여러 view에서 렌더링되며 2D augmentation을 적용하여 이미지 세트를 얻는다. CLIP 임베딩된 이미지와 원하는 텍스트의 CLIP 임베딩을 비교하여 네트워크 최적화를 supervise한다.
1. Neural Highlighter
Neural highlighter는 좌표 $x \in \mathbb{R}^3$을 $p \in [0,1]$로 매핑하는 neural field이다. 여기서 $p$는 $x$가 텍스트 지정 영역에 속할 확률이다. Neural highlighter는 3D 좌표 $x_v = (x, y, z)$의 형태로 입력 정점 $v$를 취하고 하이라이트 확률 $p_v$를 예측하는 MLP \(\mathcal{F}_\theta\)로 표시된다.
\[\begin{equation} \mathcal{F}_\theta (x_v) = p_v \end{equation}\]이 공식을 사용하면 neural field를 쿼리하여 mesh 표면 위 (또는 근처)의 모든 3D 지점에 대한 유의미한 하이라이트 확률을 얻을 수 있다. 따라서 일단 최적화되면 네트워크 가중치는 추가 최적화 없이 localization을 동일한 객체의 다른 meshing으로 편리하게 전송한다.
Neural highlighter를 MLP로 표현하면 연속적인 localization이 생성되고 아티팩트가 줄어든다. MLP는 특히 3D 좌표와 같은 저차원 입력에서 매끄러운 솔루션 쪽으로 spectral bias를 나타낸다. 저주파 출력에 대한 바이어스는 3D highlighter가 경계가 뚜렷한 연속적인 localization을 예측하도록 장려하고 noisy한 하이라이트를 권장하지 않는다. 이러한 이유로 위치 인코딩을 사용하지 않는다.
2. Mesh Color Blending
포인트별 하이라이트 확률을 활용하여 연속적이고 미분 가능한 방식으로 mesh를 색칠하여 CLIP supervision을 위해 의미론적으로 유의미한 렌더링을 생성한다. 확률 가중 혼합을 사용하며, 여기서 각 정점 색상 $C_v$는 네트워크 예측 하이라이트 확률로 가중된 하이라이트 색상 $H$와 회색 색상 $G$의 선형 결합이다.
\[\begin{equation} C_v = p_v \cdot H + (1 − p_v) \cdot G \end{equation}\]최적화 프로세스 시작 시 모든 정점 확률이 0.5 근처에서 초기화되므로 전체 mesh가 반쯤 하이라이트된다. 최적화가 진행됨에 따라 하이라이트될 것으로 예측된 정점이 텍스트 지정 영역에 부착되도록 정점이 회색 또는 하이라이트 색상 (네트워크 예측 기반)으로 부드럽게 전환된다. 이 공식은 최적화의 각 단계를 CLIP에 의미론적으로 유의미한 컬러 mesh로 변환한다. 본 논문의 방법은 하이라이트 확률의 argmax에 따라 정점을 색칠하는 것과는 대조적으로 연속적인 기울기를 제공한다. 본 논문의 혼합 체계는 보다 부드러운 최적화 환경을 제공하고 하이라이트 아티팩트를 줄인다.
이 공식은 localization을 사용하려는 다운스트림 애플리케이션 (ex. 편집, stylization)에도 중요하다. 포인트별 하이라이트 확률을 예측하면 mesh 표면의 하이라이트 영역을 명시적으로 표현할 수 있다. 표면 색상을 직접 최적화하는 다른 접근 방식은 localization에 속하는 정점에 대한 명시적인 정보 없이 시각적 결과만 제공한다.
3. Unsupervised Guidance
CLIP의 공동 비전-언어 임베딩 공간을 사용하여 최적화를 가이드한다. 입력 mesh와 타겟 localization 사이의 연관성을 설명하여 원하는 하이라이트를 공식화한다. 구체적으로 타겟 텍스트 $T$를 “a gray [object] with highlighted [region].”으로 설계한다. Differentiable rendering을 사용하여 여러 view에서 하이라이트된 형상을 렌더링한다. 각 최적화 단계에서 기본 view를 중심으로 하는 가우시안 분포에서 $n$개의 view를 랜덤하게 샘플링한다. 이렇게 하면 CLIP에 표시되는 대부분의 view에서 기본 개체를 인식할 수 있다.
시점 예측 단계에서 mesh의 360도 view를 렌더링하고 타겟 텍스트 프롬프트에 대한 CLIP 유사도를 측정한다. CLIP 유사도가 가장 높은 렌더가 될 기본 view를 선택한다. 저자들은 바람직한 하이라이트 결과를 생성 가능한 많은 시점이 존재한다는 것을 발견했다.
각 view $\psi$에 대해 2D 이미지 $I_\psi$를 렌더링하고 이전 연구들에서 수행한 것처럼 임의의 시점의 2D augmentation $\phi$를 적용한다. 그런 다음 $E_I$로 표시되는 CLIP의 이미지 인코더를 사용하여 각 augmentation 이미지를 CLIP 임베딩 공간 (\mathbb{R}^{768})으로 인코딩한다. 최종 집계 이미지 표현 $e_I$는 모든 view에 대한 평균 CLIP 인코딩이다.
\[\begin{equation} e_I = \frac{1}{n} \sum_\psi E_I (\phi (I_\psi)) \in \mathbb{R}^{768} \end{equation}\]마찬가지로 타겟 선택 텍스트 $T$를 CLIP의 텍스트 인코더 $E_T$로 인코딩하여 인코딩된 타겟 표현 $e_T = E_T (T) \in \mathbb{R}^{768}$을 얻는다. Nueral hyperparameter 파라미터 $\theta$를 최적화하기 위한 loss $\mathcal{L}$은 집계 이미지 임베딩과 텍스트 임베딩 간의 음의 코사인 유사도 (negative cosine similarity)로 공식화된다.
\[\begin{equation} \underset{\theta}{\arg \min} \mathcal{L} (\theta) = - \frac{e_I \cdot e_T}{\vert e_I \vert \cdot \vert e_T \vert} \end{equation}\]Loss가 최소화되면 렌더링된 하이라이트된 mesh의 CLIP 임베딩이 타겟 텍스트 임베딩과 유사해진다. 따라서 localize된 영역은 타겟 텍스트 영역을 반영한다.
Experiments
3D Highlighter는 mesh 품질에 제한을 두지 않는다. 사용된 많은 mesh에는 다양하지 않고 방향이 지정되지 않았으며 경계 또는 self-intersection을 포함하는 요소와 같은 아티팩트가 포함되어 있다. PyTorch 구현 최적화는 Nvidia A40 GPU에서 실행하는 데 약 5분이 걸린다. 실험에서는 224$\times$224 해상도의 CLIP ViT-L/14를 사용되었다.
1. Generality and Fidelity of 3D Highlighter
다음은 존재하지 않는 부분을 하이라이트한 일반화 결과이다.
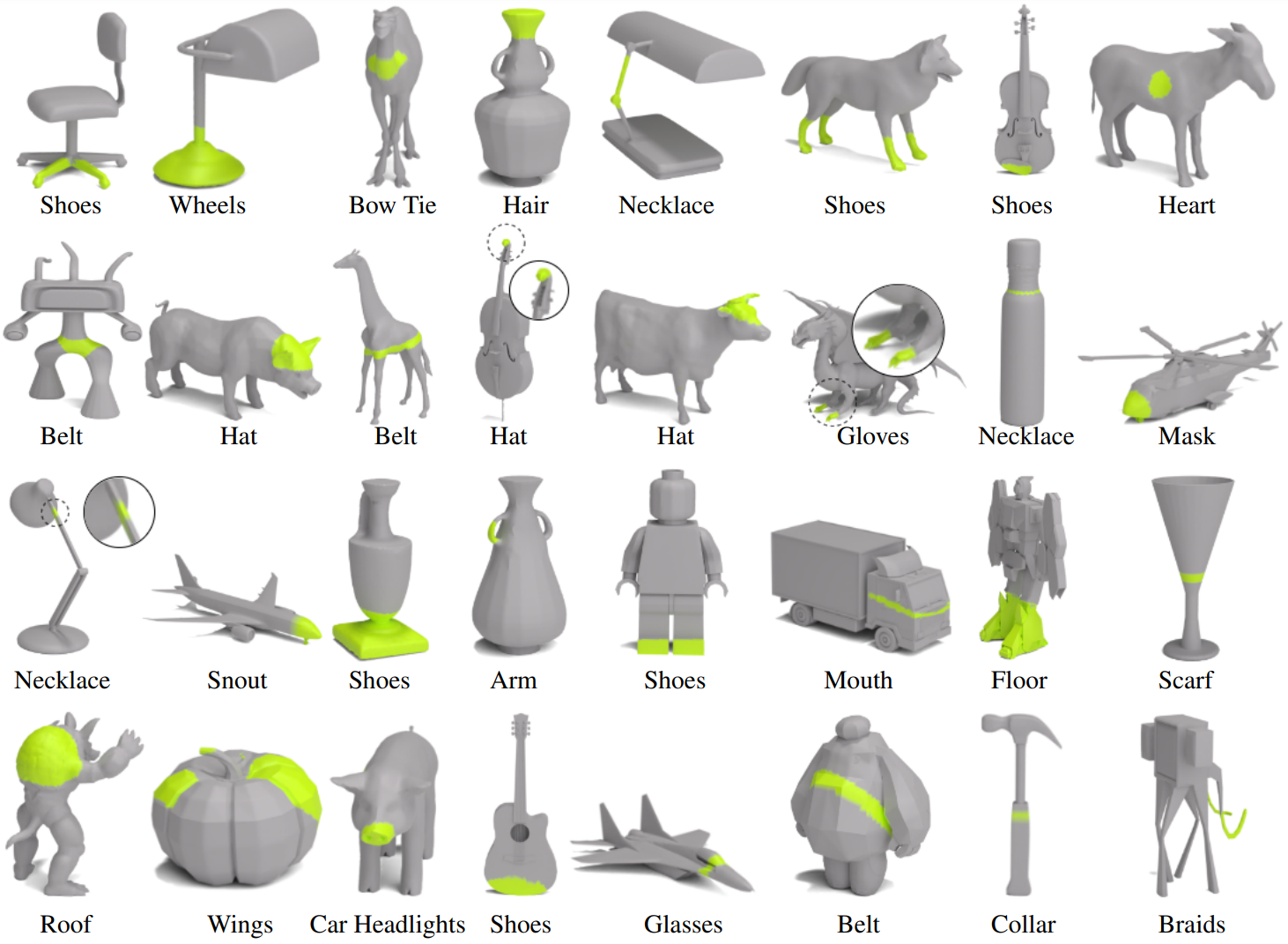
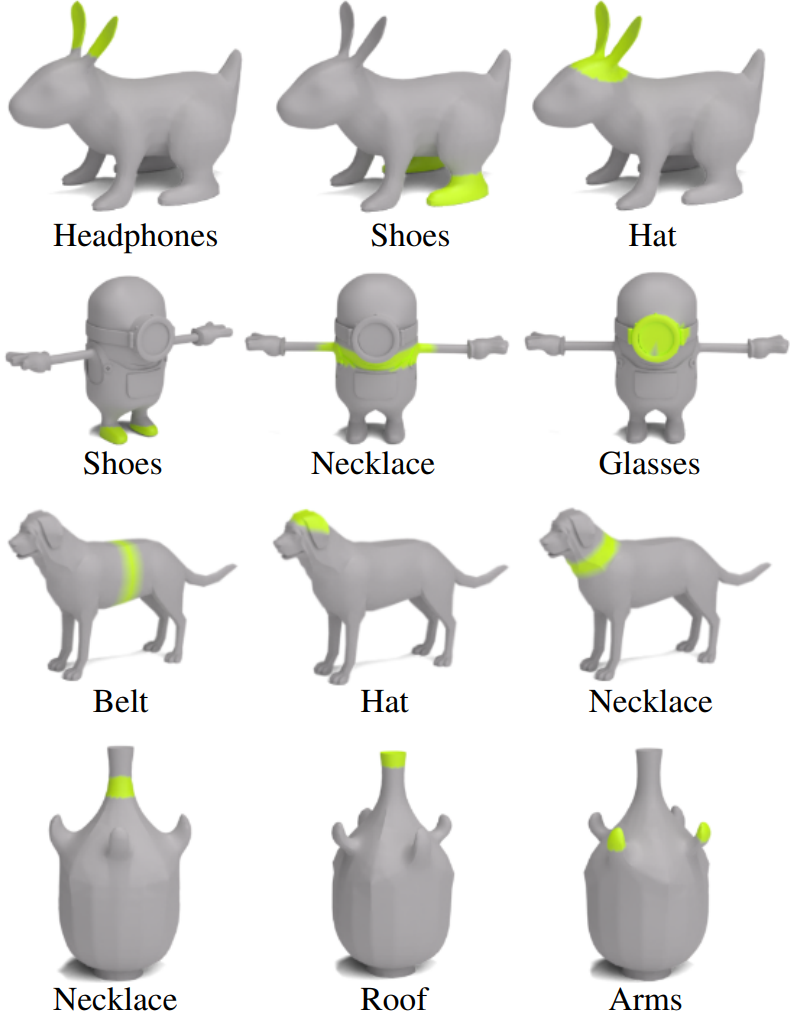
다음은 동일한 객체에 대하여 다양한 부분을 하이라이트한 결과이다.
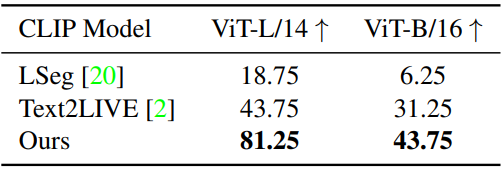
다음은 하이라이트 충실도를 나타낸 표이다.
2. Robustness of 3D Highlighter
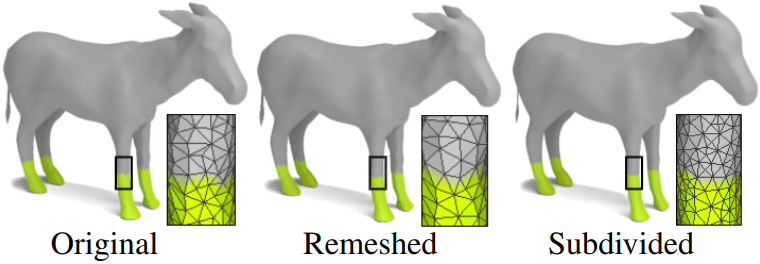
다음은 서로 다른 meshing 간에 localization 결과를 전송한 예시이다.
다음은 3가지 서로 다른 시점에 대한 하이라이트 결과이다.

3. Applications of 3D Highlighter
다음은 3D Highlighter를 사용하여 semantic 영역 내에서 3D 객체를 선택적으로 편집한 결과이다.

다음은 3가지 stylization이 주어질 때 3D Highlighter를 사용하여 서로 다른 영역을 선택하고 함께 결합한 결과이다.

다음은 독특한 기하학적 부품에 대한 semantic segmentation 결과이다.
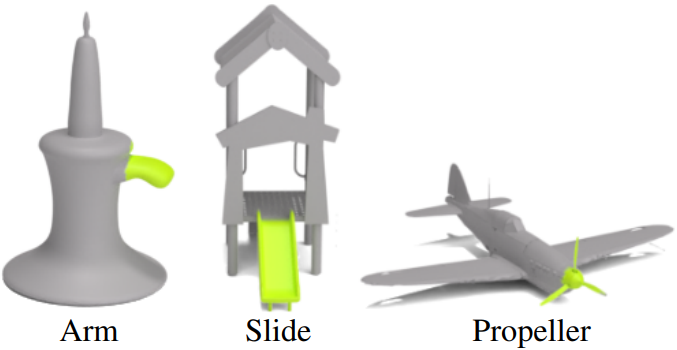
4. Components of 3D Highlighter
다음은 ablation 결과이다. 아래의 값은 CLIP 점수이다.

다음은 CLIP 점수를 ‘gray chair with highlighted back’ (왼쪽)과 ‘blue chair with red back’ (오른쪽)의 두 가지 프롬프트에 대해 분석한 것이다. 각 프롬프트에 대해 올바른 할당과 뒤집힌 할당의 렌더링에 대한 CLIP 유사도를 측정한 것이다.

다음은 세 가지 다른 초기화를 사용한 최적화 결과이다. (텍스트 프롬프트: belt)

5. Limitations
3D Highlighter는 타겟 프롬프트에서 객체 설명의 변형에 강력하다. 그러나 3D 모양과 해당 설명 사이에는 여전히 논리적 연결이 있어야 한다. 아래 그림은 낙타 mesh와 타겟 하이라이트 ‘정강이 보호대 (shinguard)’에 대한 결과를 보여준다. 각 최적화에 대해 객체 설명을 변경하여 약간 다른 타겟 프롬프트를 사용한다. 프롬프트는 “[object] with highlighted shinguards” 형식이며 여기서 [object]는 낙타, 돼지, 동물, 의자로 대체된다.
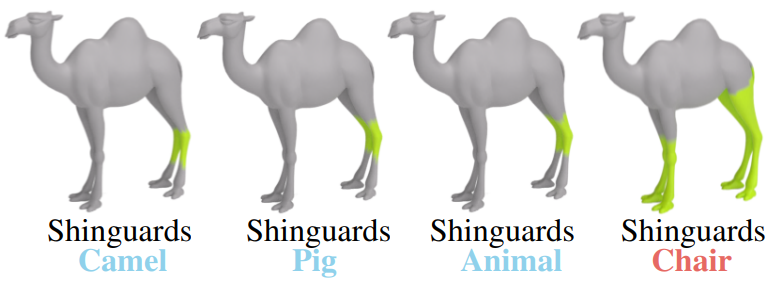
돼지, 동물 등 낙타의 형상과 유사한 객체 설명의 경우 3D Highlighter가 원하는 영역을 정확하게 localize한다. 그러나 객체의 기하학과 양립할 수 없는 설명 (즉, 낙타를 의자로 언급)의 경우 유의미한 결과를 생성하지 않는다. 이 결과는 텍스트 설명에 대한 3D Highlighter의 견고성을 보여준다. 3D Highlighter는 설명이 완벽하게 정확하지 않더라도 실제 설명과 충분히 유사한 경우 mesh에 대해 추론할 수 있다.