[논문리뷰] 360-GS: Layout-guided Panoramic Gaussian Splatting For Indoor Roaming
arXiv 2024. [Paper]
Jiayang Bai, Letian Huang, Jie Guo, Wen Gong, Yuanqi Li, Yanwen Guo
Nanjing University
1 Feb 2024
Introduction
최근에는 포인트 기반 표현인 3D Gaussian Splatting(3D-GS)가 NeRF 기반 방법과 비슷한 렌더링 품질로 실시간 속도를 달성하는 대체 표현으로 등장했다. 이 유망한 기술을 통해 실시간으로 실내 공간을 돌아다닐 수 있다.
그러나 3D-GS는 주로 perspective image에 중점을 둔다. 일련의 실내 파노라마가 제공되면 3D-GS로 새로운 뷰를 합성하는 데 몇 가지 어려움이 있다.
- 파노라마 이미지에 3D Gaussian을 splatting하면 perspective projection의 이미지 평면에 splatting된 2D Gaussian으로 모델링할 수 없는 공간 왜곡이 발생한다. 따라서 파노라마 이미지로 3D Gaussian을 직접 최적화하는 것은 불가능하다.
- 장면의 dense한 파노라마 뷰를 수집하는 데는 비용과 시간이 많이 소요되는 경우가 많다. 일반적인 이미지 수집 프로세스에서 360도 카메라는 일반적으로 방의 중앙이나 제한된 위치에 배치되므로 입력이 sparse하게 된다. 이러한 입력 부족은 2D 이미지에서 3D 구조를 학습하는 데 따른 모호성을 크게 악화시켜 불만족스러운 렌더링으로 이어진다. 많은 연구들에서 depth supervision이나 cross-view semantic consistency와 같은 픽셀별 정보를 활용하여 few-shot task를 해결하려고 시도했지만 파노라마 내의 장면 수준 구조 정보는 아직 충분히 활용되지 않고 있다.
- 실내 장면에는 벽, 바닥, 테이블, 천장과 같이 텍스처가 없고 평평한 영역이 많이 포함되어 있어 뷰 사이의 correspondence들을 찾기가 어려운 경우가 많다. 3D-GS는 학습 이미지의 픽셀에 잘 맞을 수 있지만 이러한 평면의 형상이 부정확하여 새로운 뷰에서 평면 위에 floater가 표시된다. 이전 연구에서는 기하학적 정규화를 통해 이 문제를 해결했지만 대부분은 NeRF를 기반으로 구축되었다.
앞서 언급한 문제들을 해결하기 위해 본 논문은 sparse한 파노라마 이미지용으로 설계된 새로운 레이아웃 기반 3D-GS 파이프라인인 360-GS를 제안하였다. 이 접근 방식은 고품질의 새로운 뷰를 제공하면서 실시간 파노라마 렌더링을 달성하고 floater와 같은 원하지 않는 아티팩트를 크게 줄인다. 인상적인 성능은 360-GS의 두 가지 핵심 구성 요소, 360° Gaussian splatting과 room layout prior에 기인한다. 360° Gaussian splatting은 3D Gaussian을 파노라마 입력의 단위 구에 표시하는 것을 목표로 한다. 저자들은 공간적으로 왜곡된 projection이 Gaussian으로 모델링하기 어렵다는 것을 발견했다. 따라서 360° Gaussian splatting 알고리즘은 splatting을 두 단계, 즉 3D Gaussian을 접평면에 투영한 다음 이를 구면에 매핑하는 두 단계로 분해한다. 분해는 실시간 성능을 유지하면서 projection의 복잡한 표현을 방지한다.
또한 저자들은 room layout prior를 도입하여 적은 수의 입력과 텍스처가 없는 평면으로 인해 제약이 부족한 문제를 추가로 해결하였다. 전체 시야를 갖춘 파노라마에는 본질적으로 더 많은 정규화에 활용할 수 있는 perspective image보다 더 풍부한 글로벌 구조 정보가 포함되어 있다. 방의 레이아웃은 실내 장면에 대한 가장 일반적이고 쉽게 얻을 수 있는 구조 정보이다. 방 레이아웃에서 3D Gaussian 초기화를 위한 고품질 포인트 클라우드를 추출한다. 방 레이아웃은 평평한 벽, 바닥 및 천장이 있는 장면을 설명하므로 이러한 영역의 3D Gaussian 위치에 대한 제약을 추가로 적용한다. 레이아웃 기반 초기화 및 정규화는 평면을 생성하고 새로운 뷰에서 원하지 않는 floater를 줄이는 데 도움이 된다.
Method
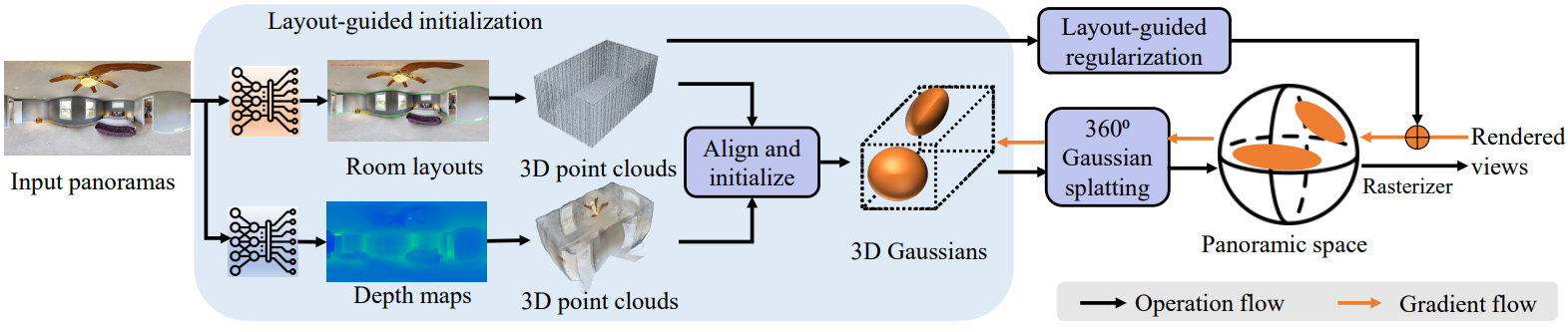
본 논문은 3D Gaussian을 최적화하고 파노라마 렌더링을 용이하게 하기 위해 설계된 파이프라인인 360-GS를 제시하였다. 위 그림은 360-GS의 개요를 보여준다. 저자들은 파노라마를 3D-GS에 적용하는 데 따른 어려움을 확인하고 해결책으로 360° Gaussian splatting을 제안하였다. 360-GS는 파노라마 입력 내에서 방 레이아웃을 완전히 활용하기 위해 레이아웃 기반 초기화 및 정규화를 추가로 설계하였다.
1. Preliminary and challenge
3D-GS는 월드 공간에서 3D Gaussian들이 포함된 3D 장면을 명시적으로 나타낸다. 각 Gaussian은 위치 벡터 $\boldsymbol{\mu} \in \mathbb{R}^3$와 공분산 행렬 $\Sigma \in \mathbb{R}^{3 \times 3}$으로 정의된다. 3D Gaussian 분포는 다음과 같이 나타낼 수 있다.
\[\begin{equation} G(\mathbf{x}) = \exp (-\frac{1}{2} (\mathbf{x} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu})) \end{equation}\]여기서 $\Sigma$는 다음과 같이 scaling matrix $\mathbf{S}$와 rotation matrix $\mathbf{R}$로 설명할 수 있다.
\[\begin{equation} \Sigma = \mathbf{R} \mathbf{S} \mathbf{S}^\top \mathbf{R}^\top \end{equation}\]미분 가능한 최적화를 위해 3D-GS는 3D Gaussian을 2D 이미지 평면에 투영하여 2D 이미지를 렌더링한다. 월드 좌표에서 점 $\mathbf{x} = (x_0, x_1, x_2)$가 주어지면 먼저 viewing transformation라고 부르는 affine mapping $\mathbf{t} = V(\mathbf{x}) = \mathbf{W} \mathbf{x} + \mathbf{d}$를 사용하여 이를 카메라 좌표 $\mathbf{t} = (t_0, t_1, t_2)$로 변환한다. 이후 카메라 좌표는 $\mathbf{x} = p(\mathbf{t})$ 매핑을 통해 광선 좌표로 변환된다.
Perspective image를 입력으로 사용하면 이러한 매핑은 실제로 affine이 아니다. 이 문제를 해결하기 위해 Jacobian matrix $\mathbf{J}$를 사용한 projective transformation의 local affine approximation이 도입되었다. 결과적으로 카메라 좌표에 투영된 2D Gaussian의 새로운 공분산 행렬 $\Sigma^\prime$은 다음과 같다.
\[\begin{equation} \Sigma^\prime = \mathbf{J} \mathbf{W} \Sigma \mathbf{W}^\top \mathbf{J}^\top \end{equation}\]3D-GS는 $\Sigma^\prime$의 세 번째 행과 열을 건너뛰어 구조와 속성이 동일한 2$\times$2 분산 행렬을 생성한다. 따라서 3D Gaussian의 projection은 2D Gaussian으로 표현된다.
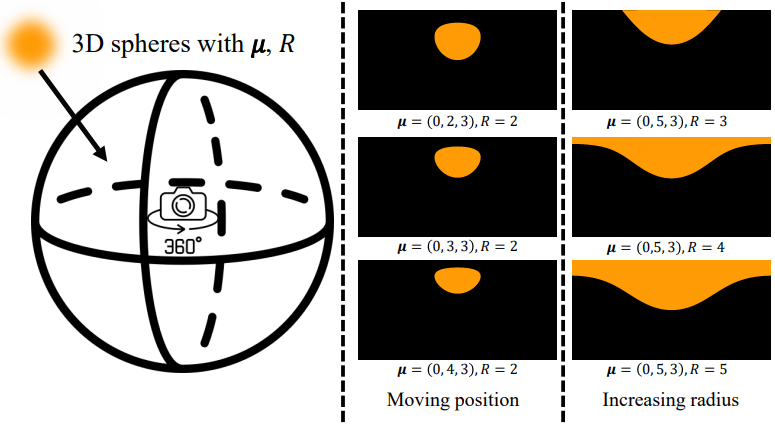
Local affine approximation은 projective transformation에 의존하기 때문에 파노라마 이미지에서 3D Gaussian을 2D Gaussian으로 매핑하는 데 적합하지 않다. 파노라마 이미지는 수평으로 360도 전체, 수직으로 180도 전체를 포괄한다. 결과적으로 이미지의 위쪽과 아래쪽이 심하게 왜곡되어 나타난다. 위 그림에서 볼 수 있듯이 파노라마의 projection은 Gaussian으로 모델링할 수 없는 독특한 모양을 가정한다. 그러한 projection을 맞추기 위해 2D Gaussian을 사용하면 심각한 오차가 발생할 수 있다.
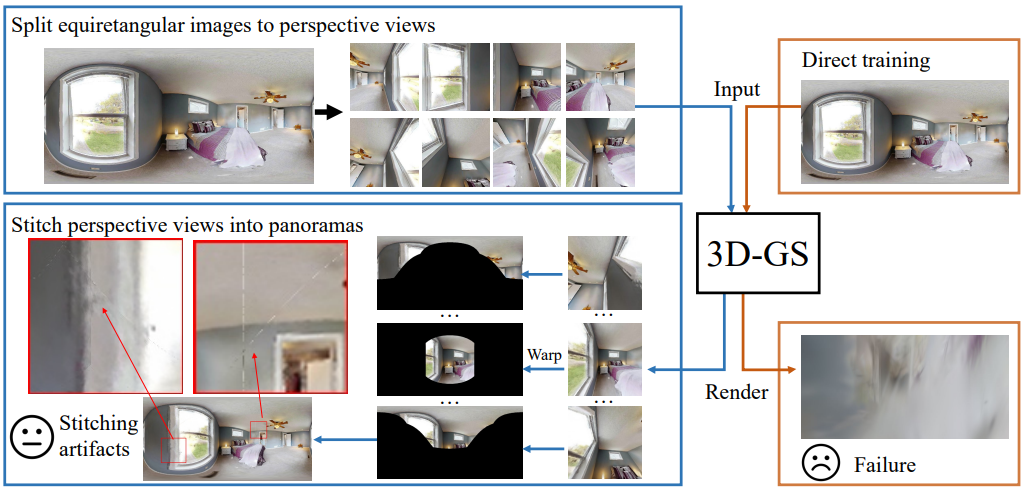
파노라마 입력에 3D-GS를 적용하기 위한 대체 접근 방식은 3D Gaussian을 최적화하기 전에 파노라마를 perspective image로 변환하는 것이다. 이 방법의 개요는 위 그림에 설명되어 있다. Equirectangular image를 각각 고유한 포즈와 관련된 $N$개의 perspective view로 분할한다. 그런 다음 이러한 perspective image를 활용하여 3D-GS로 3D Gaussian을 최적화할 수 있다. 그러나 이 간단한 솔루션에는 두 가지 주요 단점이 있다.
- 전체 파이프라인이 복잡하고 파노라마를 직접 획득하는 것이 불가능하다.
- 완전한 파노라마를 얻으려면 6개 이상의 원근 이미지를 함께 렌더링하고 연결해야 한다. 이 연결은 재구성된 파노라마의 겹치는 영역에 불가피한 스티칭 아티팩트를 발생시킨다.
2. 360° Gaussian splatting
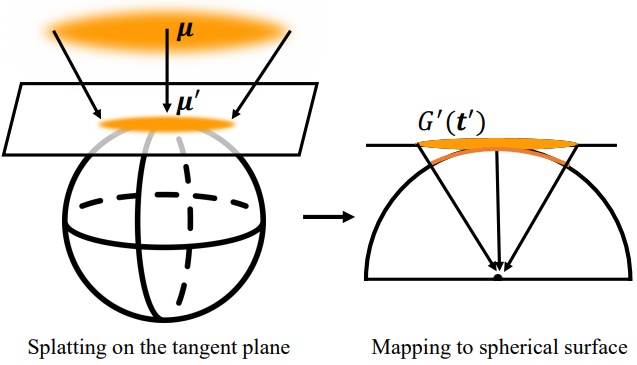
본 논문의 목표는 일련의 파노라마에서 3D Gaussian 표현을 최적화하고 직접적인 파노라마 렌더링을 가능하게 하는 것이다. Spherical projection을 직접 표현하는 어려움을 고려하여 구면의 splatting을 두 가지 순차적 단계, 즉 단위 구의 접평면에 splatting하고 구면에 매핑하는 새로운 splatting 기술을 도입하였다. 이를 통해 렌더링을 위해 3D Gaussian을 2D Gaussian으로 투영할 수 있다. 360° Gaussian splatting의 개요는 위 그림에 나와 있다.
공분산 행렬 $\Sigma$를 사용하여 $\boldsymbol{\mu}$를 중심으로 하는 3D Gaussian이 주어지면 먼저 affine viewing transformation $V(\textbf{x})$를 사용하여 이를 카메라 좌표로 변환한다. Viewing transformation 후에는 카메라 좌표를 단위 구의 접평면에 투영하는 projective transformation $\textbf{t}^\prime = \phi (\textbf{t}, \boldsymbol{\mu}^\prime)$이 이어진다. 이 접평면은 projection point $\boldsymbol{\mu}^\prime$을 통과하며 카메라 좌표의 원점을 중심으로 하는 단위 구에 접한다. Transformation은 다음과 같이 공식화된다.
\[\begin{equation} \boldsymbol{\mu}^\prime (\mathbf{x} - \boldsymbol{\mu}) = 0 \end{equation}\]여기서 $\boldsymbol{\mu}^\prime$는 $V(\boldsymbol{\mu})$를 단위 구에 투영한 것이다. 따라서 projection은 다음과 같다.
\[\begin{equation} (t_0^\prime, t_1^\prime, t_2^\prime)^\top = \phi (\mathbf{t}, \boldsymbol{\mu}^\prime) = \mathbf{t} \frac{(\boldsymbol{\mu}^\prime)^\top \boldsymbol{\mu}^\prime}{(\boldsymbol{\mu}^\prime)^\top \mathbf{t}} \end{equation}\]점 \(\textbf{t}_k\)에서의 $\phi$의 테일러 전개의 처음 두 항으로 local affine approximation $\phi_k (\mathbf{t}, \boldsymbol{\mu}^\prime)$을 정의한다.
\[\begin{equation} \phi_k (\mathbf{t}, \boldsymbol{\mu}^\prime) = \phi_k (\mathbf{t}_k, \boldsymbol{\mu}^\prime) + \mathbf{J}_k \cdot (\mathbf{t} - \mathbf{t}_k) \end{equation}\]여기서 \(\textbf{t}_k = (t_0, t_1, t_2)^\top = V(\boldsymbol{\mu})\)는 카메라 좌표에서 3D Gaussian의 중심이다. Jacobian matrix \(\textbf{J}_k\)은 점 \(\textbf{t}_k\)에서의 $\phi$의 편도함수이다.
\[\begin{equation} \textbf{J}_k = \frac{-1}{(\mu_0^\prime t_0 + \mu_1^\prime t_1 + \mu_2^\prime t_2)^2} \begin{bmatrix} \mu_1^\prime t_1 + \mu_2^\prime t_2 & \mu_1^\prime t_0 & \mu_2^\prime t_0 \\ \mu_0^\prime t_1 & \mu_0^\prime t_0 + \mu_2^\prime t_2 & \mu_2^\prime t_1 \\ \mu_0^\prime t_2 & \mu_1^\prime t_2 & \mu_0^\prime t_0 + \mu_1^\prime t_1 \end{bmatrix} \end{equation}\]$\textbf{t} = V(\textbf{x})$와 \(\textbf{t}^\prime = \phi (\textbf{t}, \boldsymbol{\mu}^\prime)\)을 concatenate하여 3D Gaussian을 접평면에 splatting하고 다음과 같이 분포를 얻는다.
\[\begin{equation} G^\prime (\textbf{t}^\prime) = \exp (-\frac{1}{2} (\textbf{t}^\prime - \boldsymbol{\mu}^\prime)^\top (\textbf{J}_k \textbf{W} \Sigma \textbf{W}^\top \textbf{J}_k^\top)^{-1} (\textbf{t}^\prime - \boldsymbol{\mu}^\prime)) \end{equation}\]파노라마 렌더링을 위해 카메라 좌표의 접평면을 구면좌표계의 구면에 매핑한다. 따라서 매핑 $(\theta, \phi) = P_{360} (\textbf{t}^\prime)$은 다음과 같다.
\[\begin{equation} \begin{pmatrix} \theta \\ \phi \end{pmatrix} = P_{360} (\textbf{t}^\prime) = \begin{pmatrix} \textrm{atan2} (-t_1, \sqrt{t_0^2 + t_2^2}) \\ \textrm{atan2} (t_0, t_2) \end{pmatrix} \end{equation}\]여기서 \(\textbf{t}^\prime = (t_0^\prime, t_1^\prime, t_2^\prime)^\top\)은 접평면 위의 점이고 $(\theta, \phi)$는 구면의 위도와 경도이다. 구면과 파노라마 픽셀 그리드 좌표는 다음과 같이 연관된다.
\[\begin{equation} \begin{cases} r = -\theta \cdot H / \pi + H / 2 \\ c = \phi \cdot W / 2\pi + W / 2 \end{cases} \end{equation}\]여기서 $(r, c)$는 해상도가 $H \times W$인 파노라마의 행과 열이다.
Projection과 일대일 매핑을 통해 3D Gaussian이 파노라마에 splatting된다. 매핑 프로세스가 효율적이기 때문에 실시간 성능을 유지한다. 그 후, 파노라마의 픽셀 색상은 3D-GS를 따라 Gaussian들을 앞에서 뒤로 알파 블렌딩하여 얻어진다. 결과적으로 파노라마를 직접적으로 렌더링할 수 있게 된다.
3. Layout prior for panoramas
3D 정보가 부족한 sparse한 파노라마의 맥락에서 3D-GS는 뷰 사이의 3D correspondence들을 식별하고 장면의 기하학적 구조를 구성하는 데 어려움을 겪어 새로운 뷰 합성 품질이 크게 저하된다. 본 논문에서는 이러한 문제를 완화하기 위해 파노라마 내 3D 구조 정보의 한 형태인 방의 레이아웃을 활용한다. 3D Gaussian으로 방 레이아웃을 통합하면 세 가지 장점이 있다.
- 다양한 시점에서 일관된 전체 방의 컨텍스트 정보와 3D prior를 포함한다.
- Depth map이나 포인트 클라우드 표현과 달리 방 레이아웃은 매끄러운 표면 구조로 장면을 설명하여 벽과 바닥을 포함한 매끄러운 평면을 생성한다.
- 방 레이아웃은 쉽게 얻을 수 있고 장면 스케일에 robust하다.
최근 발전으로 레이아웃 추정 분야가 크게 발전하여 20FPS의 프레임 속도를 달성했다.
방 레이아웃은 수직 벽, 수평 바닥, 천장으로 구성된다고 가정한다. 바닥 벽 경계 \(\textbf{B}_f \in \mathbb{R}^{1 \times W}\)와 천장 벽 경계 \(\textbf{B}_c \in \mathbb{R}^{1 \times W}\)를 사용하여 방 레이아웃을 묘사한다. 여기서 \(\textbf{B}_f\)와 \(\textbf{B}_c\)는 각 이미지 열의 천장과 바닥 경계의 위도를 나타낸다. 알려진 카메라 높이를 사용하여 이미지에서 2D 경계를 3D 위치로 변환한다. 그 후 바닥, 천장, 벽면을 복구한다. 이를 통해 장면의 3D 방 레이아웃으로 3D bounding box를 생성한다.
4. Layout-guided initialization
이전 연구들에서는 3D Gaussian 학습에서 합리적인 기하학적 초기화의 중요성을 입증했다. 3D-GS는 Structure-from-Motion (SfM)에서 파생된 초기의 sparse한 포인트들로 시작한다. 그러나 Sfm은 sparse한 뷰 입력으로 인해 실패하므로 포인트 클라우드 초기화를 안정적으로 제공할 수 없다.
방 레이아웃이 장면의 전체적인 기하학적 구조를 드러낸다는 점을 고려하여 layout point cloud를 초기화에 통합한다. 구체적으로 HorizonNet을 사용하여 각 파노라마의 레이아웃으로 바닥-벽 경계와 천장-벽 경계를 추정한다. 장면의 글로벌한 레이아웃을 얻기 위해 2D union 연산을 사용하여 모든 파노라마의 경계를 병합한다. 그런 다음 글로벌 레이아웃에서 해당 3D bounding box를 구성한 다음 uniform sampling을 통해 포인트 클라우드로 변환한다. 레이아웃에 포함되지 않은 객체에 대한 정보를 늘리기 위해 파노라마의 깊이를 추정하고 depth map을 포인트 클라우드로 변환한다. 이러한 depth point cloud들을 병합한 다음 다운샘플링하여 객체의 구조를 유지하면서 포인트 수를 줄인다. 병합된 depth point cloud는 global scale factor를 사용하여 layout point cloud에 정렬된다. 마지막으로 layout point cloud와 depth point cloud를 결합하여 3D Gaussian을 초기화한다.
5. Layout-guided regularization
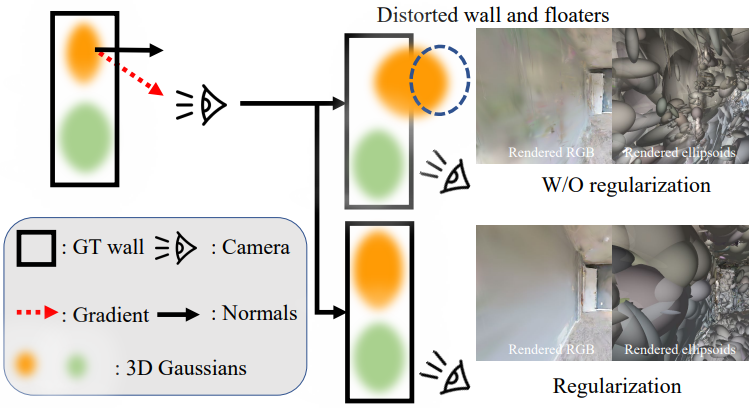
3D Gaussian은 처음에 레이아웃 기반 포인트 클라우드로 초기화되었지만 파노라마 내의 room layout prior는 catastrophic forgetting으로 인해 어려움을 겪는다. 위 그림에서 볼 수 있듯이 위치 벡터 $\boldsymbol{\mu}$와 같은 3D Gaussian의 파라미터는 기울기 방향으로 최적화된다. 결과적으로 3D-GS는 layout prior로 초기화된 기하학적 구조를 보존하기 어려워하며, 이로 인해 표면이 고르지 않고 새로운 뷰에서 “floater”가 출현하게 된다.
저자들은 이 문제를 해결하기 위해 방 레이아웃의 일관성을 유지하도록 3D Gaussian을 강제하는 레이아웃 기반 정규화를 도입했다. 특히 layout point cloud로 3D Gaussian을 초기화할 때 3D 레이아웃 포인트의 초기 위치 $\textbf{u}_0$와 법선 $\textbf{n}$을 추가로 기록해둔다. 위치의 변화와 법선 사이의 코사인 거리를 최소화하여 3D Gaussian 최적화를 정규화한다. 그런 다음 layout point cloud로 초기화된 모든 3D Gaussian에 대해 이러한 코사인 거리를 집계한다. 최종 레이아웃 기반 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{layout} = \sum \frac{\mathbf{n} \cdot (\boldsymbol{\mu} - \mathbf{u}_0)}{\| \mathbf{n} \| \times \| \boldsymbol{\mu} - \mathbf{u}_0 \|} \end{equation}\]전체 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \lambda_1 \| \textbf{C} - \hat{\textbf{C}} \|_1 + \lambda_2 \mathcal{L}_\textrm{D-SSIM} + \lambda_3 \mathcal{L}_\textrm{layout} \end{equation}\]여기서 $\textbf{C}$는 렌더링된 파노라마, $\hat{\textbf{C}}$는 ground truth 파노라마이며, \(\mathcal{L}_\textrm{D-SSIM}\)는 $\textbf{C}$와 $\hat{\textbf{C}}$ 사이의 D-SSIM loss이다.
Experiments
- 데이터셋: Matterport3D
- 구현 디테일
- 뷰 입력이 4개인 경우: \(\lambda_1\) = 0.8, \(\lambda_2\) = 0.2, \(\lambda_3\) = 0.1
- 뷰 입력이 32개인 경우: \(\lambda_1\) = 0.8, \(\lambda_2\) = 0.2, \(\lambda_3\) = 0.01
1. Results
다음은 여러 방법들과 정량적으로 비교한 표이다. M-360은 MipNeRF-360이고 INGP는 Instance NGP이다. 3D-GS*는 랜덤으로 초기화한 것이다.

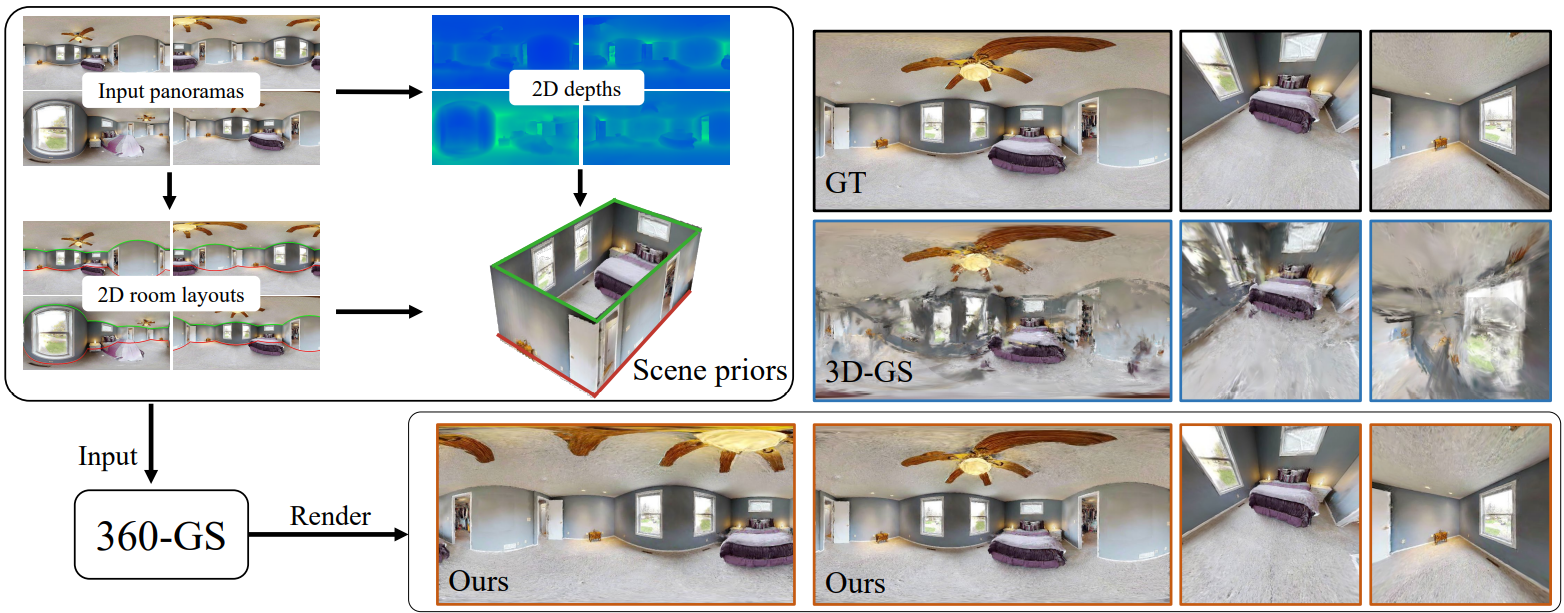
다음은 여러 방법들과 정성적으로 비교한 것이다.

2. Ablation study
다음은 ablation study 결과이다.


3. Discussion
다음은 학습 뷰의 수에 따른 영향을 비교한 표이다.
